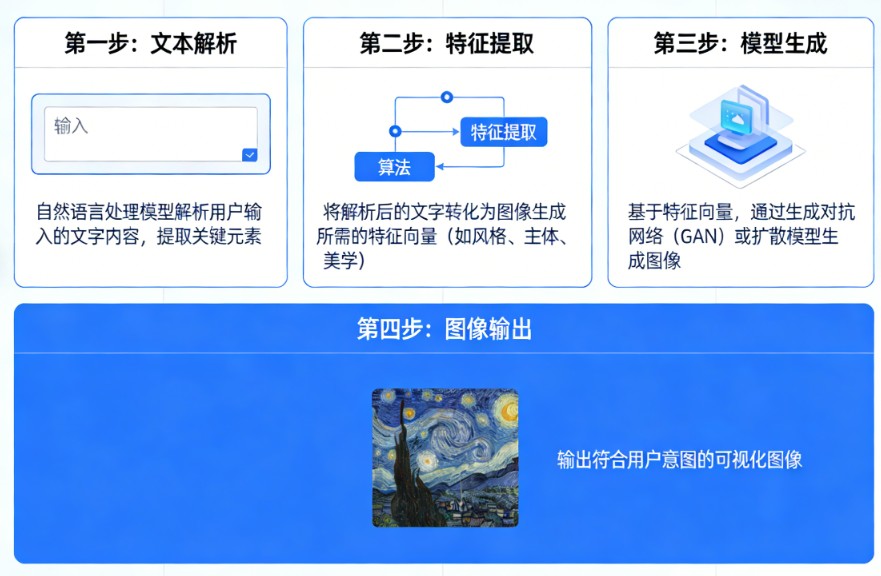
稀疏注意力机制是Transformer模型中通过限制注意力计算范围、仅关注关键信息片段的优化技术,将传统注意力机制的O(n²)计算复杂度降至O(n·k)或O(n log n),从而高效处理超长序列数据(如百万级Token文本)。它不依赖固定规则而是动态筛选重要信息,在保持模型性能的同时显著降低计算与显存开销,已成为大模型支持长上下文的关键技术。
稀疏注意力机制核心特点
1. 计算效率显著提升
- 复杂度优化:将标准注意力的二次方计算复杂度(O(n²))降低至近线性级别(O(n·k)或O(n log n)),其中k为动态选择的关键片段数量。
- 显存占用减少:通过减少需加载的KV缓存数据量,大幅缓解显存带宽瓶颈,尤其在解码阶段效果显著。
2. 动态选择关键信息
- 非固定规则:不同于滑动窗口等静态稀疏模式,现代稀疏注意力(如NSA、MoBA)能根据输入内容动态筛选最相关片段,避免关键信息遗漏。
- 硬件友好设计:通过块级操作与连续访存优化,确保理论加速能实际落地,而非仅停留在算法层面。
3. 训练与推理一致性
- 原生可训练性:先进方案(如NSA)在预训练阶段即引入稀疏机制,使模型学会主动分配注意力,避免训练-推理不一致导致的性能损失。
- 端到端兼容:支持与稠密注意力无缝切换,短序列场景无需额外开销。
稀疏注意力机制技术原理
1. “Select-then-Compute”范式
- 快速筛选:先通过轻量级索引模块快速定位与当前查询最相关的少量关键片段(如1%的Token)。
- 精准计算:仅对筛选出的片段执行标准注意力计算,跳过无关信息的冗余运算。
2. 典型实现方式
(1)多尺度信息融合架构
- 压缩分支:将远距离文本块压缩为摘要,粗粒度扫描全局上下文。
- 选择分支:动态选取与当前查询最相关的局部关键块进行细粒度计算。
- 滑动窗口分支:固定关注最近邻的局部上下文,保障短期语义连贯性。
三者通过门控机制融合输出,兼顾全局视野与局部细节。
(2)硬件对齐优化
- 块级连续访存:将序列切分为固定大小的块,确保GPU能高效加载连续数据。
- 组内共享计算:同一GQA组的注意力头共享选定的KV块,避免重复加载导致的I/O开销。
稀疏注意力机制核心功能
1. 突破长序列处理瓶颈
- 支持百万级Token上下文:使大模型能处理整本书、超长代码库或法律合同等传统难以覆盖的场景。
- 维持推理效率:在100万Token上下文下,单Token解码速度可达全注意力的10倍以上,避免因序列增长导致的指数级延迟。
2. 平衡性能与成本
- 保持模型能力:通过动态筛选关键信息,在显著降低计算量的同时,维持接近全注意力的准确率(如长文本理解任务中保留98%+性能)。
- 降低硬件门槛:减少对高端显卡的依赖,使长文本推理可在消费级设备上运行。
稀疏注意力机制应用场景
1. 超长文本理解与生成
- 法律/金融文档分析:处理整份合同或财报,精准定位关键条款。
- 代码全量分析:理解跨文件的代码逻辑依赖,支持复杂编程任务。
- 小说续写与摘要:基于完整上下文生成连贯内容,避免局部窗口导致的逻辑断裂。
2. 多模态与视频生成
- 长视频生成:在视频序列中高效捕捉跨帧关联(如HunyuanVideo 1.5的SSTA机制)。
- 跨模态对齐:处理图文混合的长文档(如PDF扫描件),精准关联文本与图像区域。
3. 推理链与复杂任务
- 思维链(CoT)扩展:支持模型进行更长的“内心独白”,完成多步骤推理。
- Agent任务执行:在操作桌面软件等跨系统任务中,维持对历史操作步骤的完整记忆。
稀疏注意力机制的本质是让模型像人类一样“选择性关注”,而非机械地处理所有信息。它通过算法创新与硬件协同设计,在不牺牲关键能力的前提下突破长序列处理瓶颈,成为大模型从聊天工具升级为专业级生产力平台的核心技术。未来随着动态稀疏策略的进一步优化(如自适应k值选择),其在复杂任务中的实用性将持续提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...