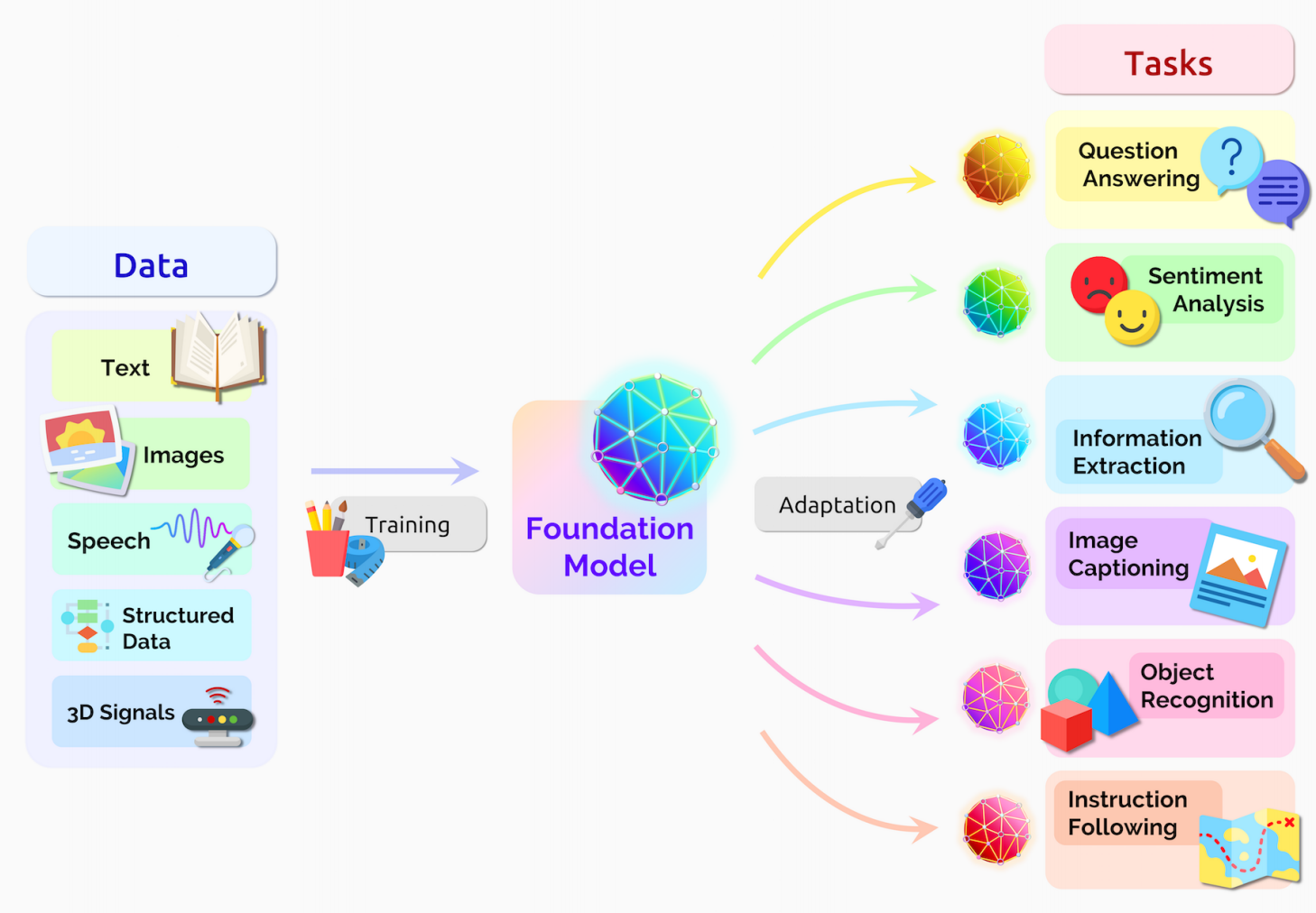
基础模型核心特点
- 任务无关性:
预训练阶段不针对特定任务,而是通过自监督学习从海量数据中提取通用模式,形成跨领域的知识表示。 - 强泛化能力:
能通过少量样本或提示词(Prompt)快速适应新任务,例如从文本生成扩展到代码编写或医学影像分析。 - 规模驱动性能:
遵循缩放定律(Scaling Law),模型性能随参数量、数据量和算力投入的增加而显著提升。 - 迁移学习基础:
作为“通用底座”,可通过微调(Fine-tuning) 或提示工程(Prompt Engineering) 适配垂直场景,避免重复训练。
基础模型技术原理
1. 自监督预训练
- 模型从无标注数据中自动生成监督信号(如预测文本掩码、图像补全),无需人工标注即可学习数据分布规律。
- 典型任务:掩码语言建模(BERT)、下一词预测(GPT)、扩散去噪(Stable Diffusion)。
2. Transformer架构
- 核心机制:通过自注意力(Self-Attention) 捕捉长距离依赖关系,替代传统RNN/CNN的序列处理限制。
- 优势:并行计算效率高,能处理超长上下文,支持多模态输入(文本、图像、音频等)。
3. 缩放定律(Scaling Law)
- 模型性能与参数量、数据量、计算量呈幂律关系,三者需同步扩展以避免收益递减。
- 例如:GPT-3(1750亿参数)在零样本任务上的表现远超小规模模型。
4. 适配技术
- 微调:在预训练权重基础上,用少量领域数据更新模型参数(如医疗BERT)。
- 提示工程:通过设计输入提示词引导模型输出,无需修改参数(如“请用法律术语解释合同条款”)。
基础模型核心功能
1. 跨模态理解与生成
- 自然语言处理:文本生成、翻译、摘要、情感分析,支持多语言交互。
- 计算机视觉:图像生成(Stable Diffusion)、目标检测、医学影像分析。
- 多模态融合:图文互译(CLIP)、视频描述生成、跨模态检索。
2. 垂直领域赋能
- 科学发现:预测蛋白质结构(AlphaFold)、生成新材料(MatterGen)。
- 专业服务:法律文书辅助、医疗诊断支持、金融风险评估。
- 工业应用:机器人运动控制(AstraBrain-WBC)、自动驾驶决策。
3. 开发效率提升
- 降低数据门槛:减少对标注数据的依赖,利用无标签数据预训练。
- 加速模型迭代:基于基础模型微调,节省90%以上训练成本。
基础模型适用人群
1. 企业开发者
- 快速落地AI应用:无需从头训练模型,直接基于开源基础模型(如Llama 3、Qwen)开发行业解决方案。
- 典型场景:客服机器人、内容生成、内部知识库问答系统。
2. 垂直领域专家
- 非AI背景的专业人士(医生、律师、工程师)可利用基础模型自动化重复性工作,例如:
- 医生:生成患者报告、辅助诊断;
- 律师:合同审查、案例检索;
- 科研人员:文献综述、实验设计。
3. 研究机构与高校
- 推动技术边界:作为研究新算法、评估道德风险的公共实验平台。
- 教育应用:辅助教学(个性化习题生成)、降低AI学习门槛。
4. 创意工作者
- 内容创作者:利用文生图/视频模型(DALL·E、Sora)加速创意流程。
- 开发者:通过代码生成模型(GitHub Copilot)提升编程效率。
基础模型的本质是人工智能的“操作系统”,其价值不仅在于技术性能,更在于推动AI从“专用工具”向“通用能力”的范式转变。企业需关注三点:选择与业务匹配的开源/闭源模型、设计高效适配流程、规避数据偏见与合规风险。对个人而言,掌握提示工程与领域知识融合能力,将成为未来竞争力的关键。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...