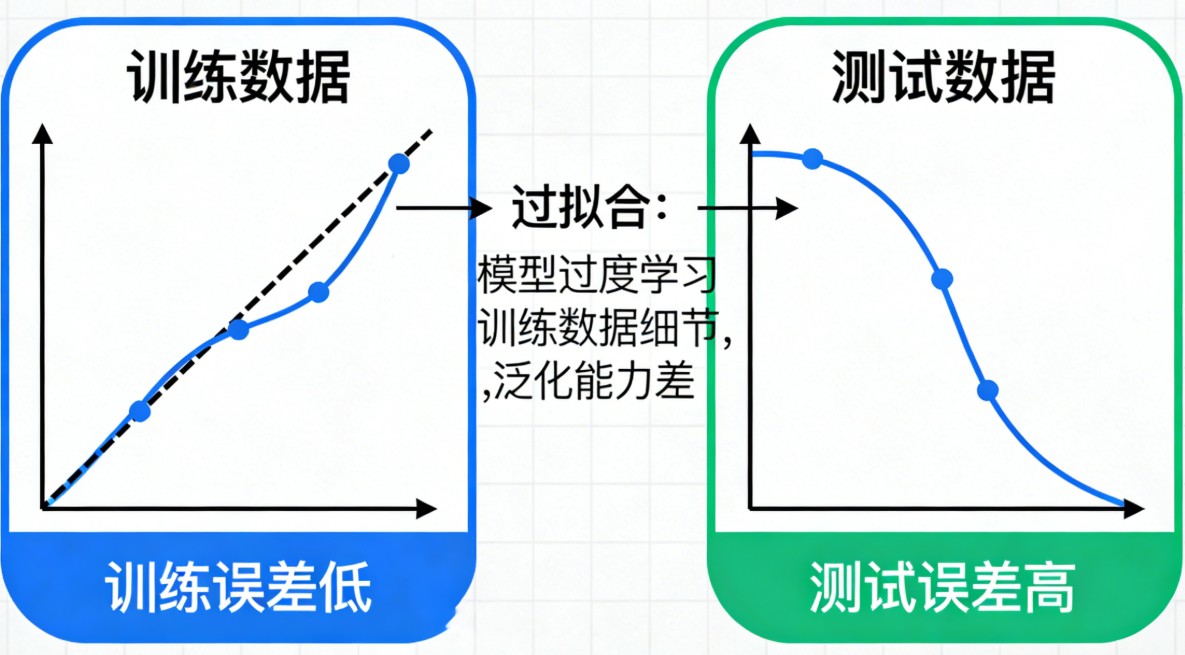
自监督学习(Self-Supervised Learning, SSL)是当前人工智能领域,尤其是大模型(如GPT系列、BERT、MAE等)背后的核心技术之一。它被图灵奖得主Yann LeCun称为“智能的暗物质”,因为它解决了AI发展中最昂贵的瓶颈——数据标注。
简单来说,自监督学习是一种让AI模型通过“做填空题”或“预测未来”来从海量无标签数据中自我学习的方法。
核心概念:AI的“自学”模式
而在自监督学习中,我们不需要人工标签。模型通过数据本身生成“伪标签”来训练自己。
- 通俗比喻: 就像教孩子认字。
- 监督学习: 拿着卡片告诉孩子“这是苹果”,“这是香蕉”。
- 自监督学习: 给孩子一本书,把其中几个字涂黑,让孩子根据上下文猜这几个字是什么。孩子在不断“猜词”的过程中,学会了语法、语义和逻辑。
它是如何工作的?
自监督学习的核心在于设计一个前置任务(Pretext Task)。这个任务的目的不是为了完成某项具体工作,而是为了强迫模型理解数据的内部结构。
主要有两种主流的实现方式:
1. 生成式/重构式(Generative/Reconstructive)
这是目前大语言模型(LLM)最常用的方式。
- 原理: 把数据的一部分遮盖住(Masking),让模型预测被遮盖的部分。
- 例子:
- 文本(BERT/GPT): 输入“今天天气真[MASK]”,模型预测“好”。或者给定前文,预测下一个字。
- 图像(MAE): 把一张图片遮住75%,让模型根据剩下的碎片还原出整张图片。为了还原图片,模型必须理解图片中的物体形状和结构,而不仅仅是像素。
2. 对比式(Contrastive Learning)
- 原理: 让模型学会“找不同”和“找相同”。
- 例子: 对同一张猫的图片进行裁剪、变色,得到两张看起来不同的图。模型的任务是识别出这两张图其实是“同一只猫”(拉近它们的距离),而与其他图片(如狗)区分开(推远距离)。
三种学习方式的对比
表格
| 维度 | 监督学习 | 无监督学习 | 自监督学习 |
|---|---|---|---|
| 数据需求 | 大量人工标注数据 | 无标签数据 | 无标签数据 |
| 训练目标 | 直接分类或预测结果 | 发现数据聚类或分布 | 完成前置任务(如填空) |
| 成本 | 极高(需要人力) | 低 | 低(利用海量现成数据) |
| 典型应用 | 传统的图像识别 | 推荐系统聚类 | ChatGPT, BERT, MAE |
为什么它如此重要?
- 打破数据瓶颈: 互联网上有无穷无尽的无标签数据(网页、视频、图片),但人工标注的数据非常稀缺。自监督学习让AI可以利用这些“免费”的数据资源。
- 构建“世界模型”: 通过在海量数据上进行自监督预训练,模型学到的不仅仅是简单的分类能力,而是对语言、视觉甚至物理世界的深层理解(即“表征”)。
- 强大的迁移能力: 经过自监督学习预训练的模型(基础模型),只需要少量的标注数据进行“微调”,就能在医疗、法律、编程等特定领域达到极高的准确率。
现实中的应用案例
- 自然语言处理(NLP): 你正在使用的千问(Qwen)、ChatGPT,以及BERT,都是通过预测下一个词(自监督)来学习人类语言的语法、逻辑和知识的。
- 计算机视觉(CV): Facebook的MAE(掩码自编码器),通过像“拼图”一样还原图片,学会了识别物体的形状和结构,效果远超传统的监督学习方法。
- 自动驾驶: 汽车通过观察视频的前几帧,预测下一帧画面会发生什么(自监督),从而学会理解物体的运动规律和深度信息。
最后想说,自监督学习是让AI从“死记硬背”(依赖标签)转向“理解规律”(自我学习)的关键技术,也是通往更高级人工智能(AGI)的必经之路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...