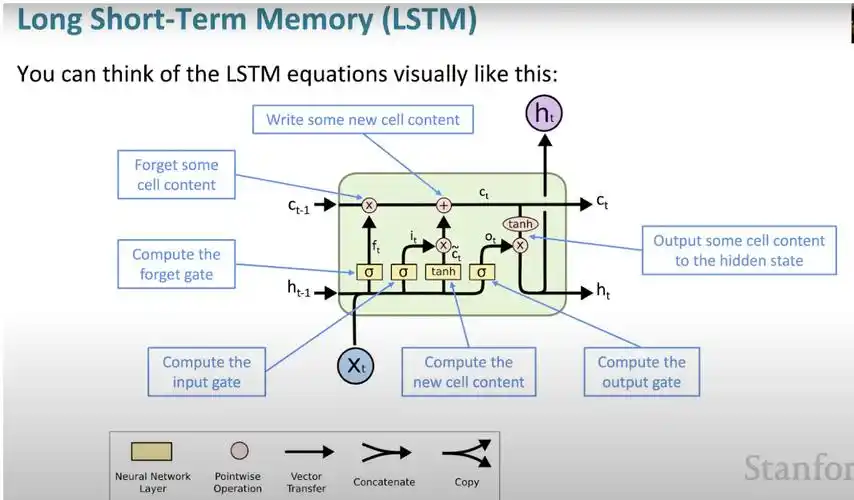
LSTM(Long Short-Term Memory),即长短期记忆网络,是深度学习领域中一种经典的循环神经网络(RNN)。它由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出,专门为解决传统RNN在处理长序列数据时面临的“长期依赖”问题而设计。
简单来说,LSTM就像一个拥有“超级记忆力”的系统,能够从海量的序列数据(如文本、语音、时间序列)中,精准地捕捉到远距离信息之间的关联。
为什么需要LSTM?
传统的RNN在处理长序列时,会面临梯度消失的问题。这就像一个记性很差的人,听到一句话的开头,等到听完结尾时,已经把开头的内容忘得一干二净了。这使得RNN难以学习到序列中相距较远元素之间的依赖关系。
LSTM通过其独特的内部结构,有效地解决了这个问题,成为了处理序列数据的王牌模型之一。
核心原理:细胞状态与“三门”调控
LSTM的核心创新在于引入了细胞状态(Cell State)和一套精密的门控机制。
- 细胞状态 (Cell State):可以把它想象成一条贯穿整个网络的“信息高速公路”或“传送带”。信息可以在这条路上几乎无损地流动,从而将长期记忆从序列的开头传递到结尾。
- 门控机制 (Gating Mechanism):LSTM通过三个“门”来精细地控制细胞状态中的信息,决定保留什么、忘记什么和输出什么。
表格
| 门的名称 | 功能 | 作用 |
|---|---|---|
| 遗忘门 (Forget Gate) | 决定“忘记什么” | 从细胞状态中丢弃不重要的旧信息。 |
| 输入门 (Input Gate) | 决定“记住什么” | 将当前时刻的新信息有选择地添加到细胞状态中。 |
| 输出门 (Output Gate) | 决定“输出什么” | 基于细胞状态,决定当前时刻要输出什么信息给下一个时间步。 |
通过这种“遗忘-记忆-输出”的循环,LSTM能够非常稳定地学习和记忆长距离的依赖关系。
LSTM vs. GRU
GRU(Gated Recurrent Unit,门控循环单元)是LSTM的一个流行变体,可以看作是LSTM的简化版。
表格
| 对比维度 | LSTM | GRU |
|---|---|---|
| 结构复杂度 | 较高,包含3个门和独立的细胞状态。 | 较低,将遗忘门和输入门合并为“更新门”。 |
| 参数量 | 较多,训练速度稍慢。 | 较少,训练速度更快。 |
| 记忆能力 | 极强,尤其适合超长序列任务。 | 较强,在多数任务上表现与LSTM相当。 |
广泛应用领域
凭借其强大的序列处理能力,LSTM在众多领域都有广泛应用:
- 自然语言处理 (NLP):如机器翻译、文本生成、情感分析等。
- 时间序列预测:如股票价格预测、天气预测、能源消耗预测等。
- 语音识别:将连续的语音信号转换为文本。
- 工业智能运维:通过分析设备传感器数据,预测潜在故障。
优缺点与现状
在Transformer等更现代的架构出现后,LSTM的地位有所变化,但它依然具有不可替代的价值。
表格
| 优点 | 缺点 |
|---|---|
| 能有效捕捉长距离依赖,缓解梯度消失问题。 | 计算无法并行,训练和推理速度较慢。 |
| 在中小规模数据集上表现稳健,不易过拟合。 | 模型结构相对复杂,超参数调优难度较大。 |
| 推理时内存占用稳定,适合在边缘设备部署。 | 在处理超长序列时,性能仍不及基于注意力机制的模型。 |
最后想说,LSTM可以被看作是处理序列数据的“精准步枪”,在数据有限、需要可解释性或要求低功耗实时推理的场景下,它依然是非常强大和可靠的选择。而Transformer则像“重型火炮”,在数据丰富、算力充足且追求极致性能的场景下更具优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...