
多模态处理是让人工智能系统同时理解、关联并生成文本、图像、音频、视频等多种信息模态的技术,突破单一模态的感知局限,实现对真实世界的综合认知与交互。与传统单模态模型相比,它能通过跨模态语义对齐和统一推理框架,解决信息碎片化、场景理解片面化等问题,成为当前AI向通用人工智能(AGI)演进的关键路径。
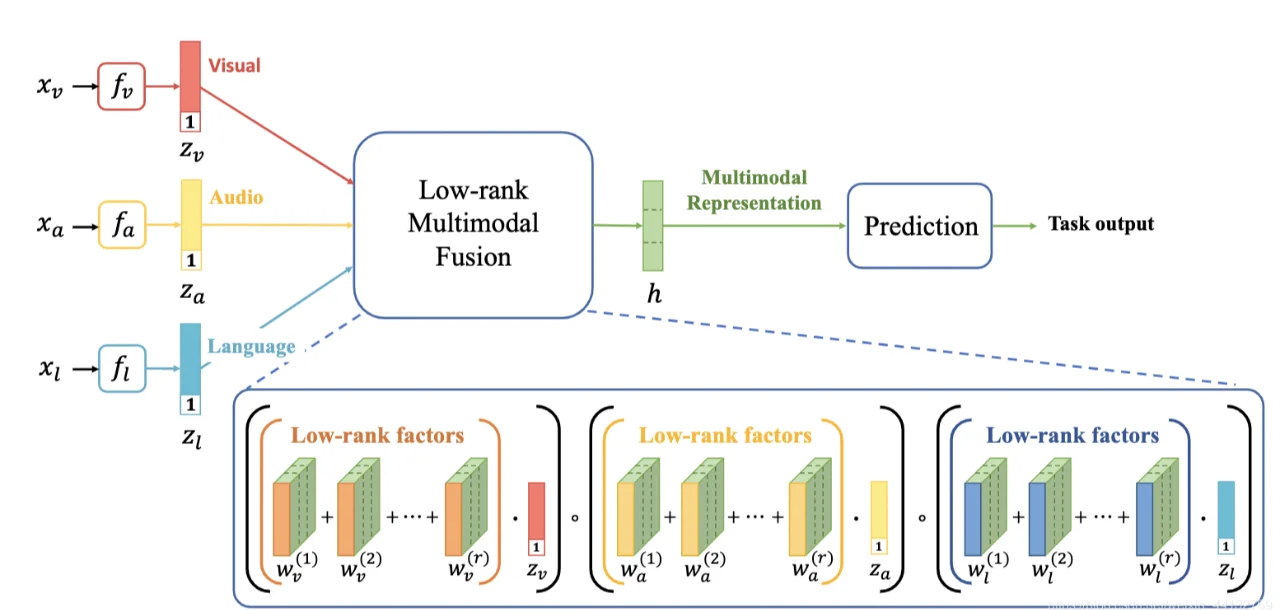
多模态处理优势
1. 跨模态对齐:消除语义鸿沟
- 模态间语义映射:
通过对比学习等技术,将不同模态的数据(如图片与描述文本)映射到统一的向量空间,使模型能识别“同一概念在不同模态中的表达”。例如,一张“猫在草地上”的图片与对应文本描述在向量空间中的距离需显著小于无关文本。 - 动态权重分配:
根据任务需求自动调整各模态的贡献度。例如,在医疗诊断中,若影像特征与文本报告冲突,系统会优先信任高置信度的影像模态,避免信息误判。
2. 统一语义空间构建
- 共享特征表示:
通过共享Transformer层或跨模态注意力机制,将视觉、文本等特征压缩到相同维度的向量空间(如768维),实现模态间直接计算相似度。 - 多粒度对齐策略:
不仅对齐全局语义(整张图片与整体描述),还需对齐局部细节(如“猫的耳朵”对应图片中的特定区域),提升细粒度理解能力。
多模态处理技术原理
1. 三段式基础架构
- 视觉/模态编码器:
使用ViT、ResNet等模型提取原始数据特征。例如,CLIP的ViT将图像切分为16×16像素块,生成视觉特征向量。 - 跨模态对齐模块:
通过MLP或交叉注意力机制,将视觉特征映射到语言模型的文本特征空间,实现模态间语义衔接。 - 大语言模型(LLM)推理层:
接收对齐后的多模态输入,统一生成文本、代码或操作指令,完成复杂推理任务。
2. 关键处理技术
- 多模态特征融合策略:
- 早期融合:直接拼接原始数据特征,适合模态同步且固定的场景(如视频字幕生成)。
- 晚期融合:独立处理各模态后加权整合,适用于异构或异步输入(如结合历史文本与实时图像)。
- 中间融合:在模型中间层通过注意力机制动态交互,效果最优但计算成本高,适用于高精度任务(如医疗影像诊断)。
- 动态模态路由:
根据输入内容自动选择关键模态路径。例如,自动驾驶中检测到行人时,系统会实时增强视觉模态的处理权重。
多模态处理应用场景与挑战
1. 高价值落地场景
- 智能文档处理:
直接解析扫描合同、带表格的PDF等非结构化文档,提取关键字段并输出结构化JSON,准确率较传统OCR提升18%以上(如物流面单识别从78%→96%)。 - 工业视觉质检:
通过“文字描述+少量样本”实现零样本缺陷检测(如“划痕>2mm”),替代90%以上人工目检,漏检率从3%降至0.5%。 - 医疗多模态诊断:
融合CT影像、电子病历文本及听诊音频,生成包含诊断依据的完整报告,准确率较单模态模型提升27%。
2. 现存技术挑战
- 计算效率瓶颈:
视觉编码与跨模态交互占推理延迟的70%以上,需通过TensorRT加速、FlashAttention算法优化。 - 数据闭环缺失:
专业场景(如法律、医疗)缺乏高质量标注数据,需构建半自动标注管道降低人工成本75%。 - 可解释性不足:
复杂推理过程常呈“黑箱”状态,需结合神经符号系统输出可追溯的推理链路(如“振动超阈值→关联轴承磨损历史记录”)。
多模态处理的核心价值在于让AI从“识别信息”升级为“理解场景”。当前技术已能较好解决图文对齐和基础推理问题,但在视频时序建模、多模态生成一致性及低资源场景适配上仍需突破。对于企业应用,建议优先从文档解析、质检等ROI明确的场景切入,采用渐进式开发策略(先文本-图像融合,再扩展音频/视频),并重点关注模态对齐精度与实时处理能力的平衡。未来,随着统一多模态架构的发展,其能力将从“辅助分析”逐步扩展至“主动决策”,成为具身智能和自动驾驶的底层支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...