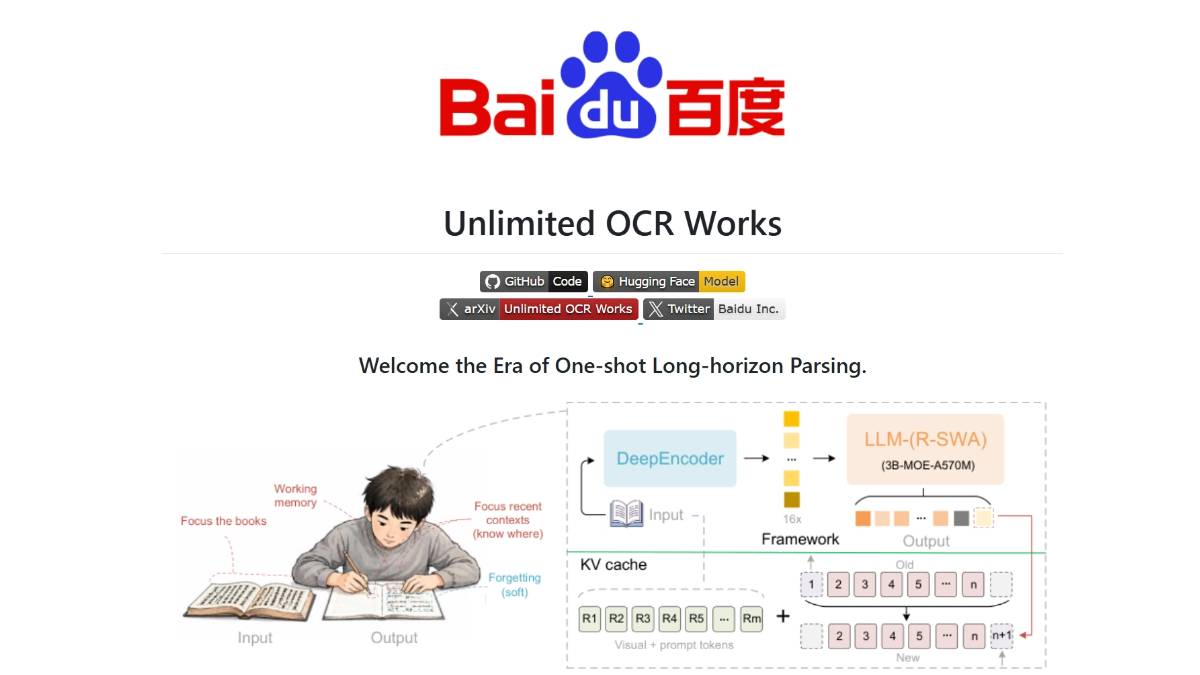
Unlimited-OCR是百度开源的端到端长文档解析视觉语言模型,通过创新的参考滑动窗口注意力机制(R-SWA),首次实现单次推理无损解析40+页PDF文档的能力,解决了传统OCR模型处理长文档时的”逐页失忆”问题。该模型以3B总参数量(激活仅500M)在OmniDocBench v1.6评测中达到93.92%的端到端SOTA成绩,显著超越参数量大数十倍的Qwen3-VL(235B)等模型,适用于需要高精度版面还原的长文档解析场景,但对简单结构化字段识别(如发票)仍推荐传统OCR方案。
Unlimited-OCR核心特点
1. 长文档一次性解析能力
- 单次推理处理40+页文档:无需逐页分割拼接,保持跨页表格、公式、阅读顺序的连贯性,避免传统方案因分页导致的结构断裂问题。
- 内存占用恒定:无论文档长度如何,KV缓存大小始终保持固定,处理40页文档时内存消耗与单页几乎一致。
2. 小模型高效率设计
- 3B总参数量,激活仅500M:远低于主流多模态模型(如Qwen3-VL的235B),但在OmniDocBench v1.6上以93.92%的Overall分数刷新SOTA,文本编辑距离低至0.038。
- 推理速度优势:输出6144个token时,吞吐量(TPS)比DeepSeek OCR高35%,且解码延迟不随文档长度增加。
3. 人类认知启发的架构
- “软遗忘”机制:模拟人类抄书时仅关注”原文全局+最近几行”的认知模式,避免无效记忆累积。
- 无需外部调度器:彻底摒弃传统OCR依赖的”逐页处理+结果拼接”工程方案,实现真正的端到端长程解析。
Unlimited-OCR技术原理
1. R-SWA注意力机制
- 参考段与滑动窗口分离:
- 参考段:始终保留全部视觉token和prompt(对应原始文档),确保全局信息可见。
- 滑动窗口:仅关注最近128个输出token(模拟人类短期记忆),新token生成时自动淘汰最早记录。
- KV缓存恒定化:通过队列结构管理缓存,内存占用与输出长度解耦,解决标准注意力机制下KV缓存随序列爆炸增长的问题。
2. DeepEncoder视觉压缩技术
- 16倍视觉token压缩率:将1024×1024分辨率的PDF页面压缩至仅256个视觉token,大幅降低prefill阶段开销。
- 视觉特征保真:压缩过程中排除视觉token参与状态转移,避免长文档解析中常见的特征模糊问题。
3. 端到端训练策略
- 基于DeepSeek OCR微调:仅需继续训练4000步即可实现长文档能力跃升,无需从头训练大模型。
- MoE架构优化:混合专家模型设计平衡效率与性能,激活参数控制在500M以内。
Unlimited-OCR核心功能
1. 高精度长文档解析
- 复杂版面还原:精准处理双栏排版、跨页表格、手写批注等场景,输出结构化Markdown/HTML(如自动补全跨页表头)。
- 多模态内容理解:同步解析文本、公式(CDM 92.61%)、表格(TEDS 90.93%),保留原始布局逻辑。
2. 企业级实用工具链
- 流式处理模式:支持按需配置分页切片(如每5页一个chunk),避免超长文档内存溢出。
- API友好集成:提供HuggingFace Transformers和SGLang部署方案,可直接嵌入RAG系统作为文档预处理模块。
3. 关键性能指标
- 40页文档编辑距离≤0.11:转录结果与原文差异极小(20页时仅0.057)。
- Distinct-35≥96.90%:生成内容重复率低于3.1%,有效避免长文本机械复读。
- 32K上下文利用率:在标准长度限制下稳定支撑40+页PDF解析。
Unlimited-OCR适用人群
1. 长文档数字化场景
- 学术与出版机构:
适用于论文、教材、古籍等长文本的结构化提取,需保留原始排版逻辑(如公式跨页连续性)。 - 企业知识库建设:
为RAG系统提供高还原度文档解析,解决传统OCR导致的段落错序、表格断裂问题。
2. 技术开发者
- 文档中台构建者:
需替代多模块流水线(检测-识别-版面分析),通过单一模型简化部署流程。 - 高性能需求场景:
对解析速度与内存效率敏感的后端服务(如日均处理万页级PDF的SaaS平台)。
3. 不适用场景
- 简单结构化字段识别:
发票、身份证等固定模板字段抽取,PaddleOCR的PP-Structure更轻量高效。 - 坐标级精度需求:
需要逐字坐标框或置信度的场景(如文档校对),传统检测+识别流水线仍是首选。 - 超高并发纯文字识别:
低复杂度文本提取任务中,PP-OCR等轻量模型更具成本优势。
最后想说
Unlimited-OCR的实质是通过认知对齐的技术路径解决长文档OCR的工程瓶颈:
- 技术层面,其R-SWA机制将KV缓存从线性增长转化为恒定占用,使小模型也能处理超长序列;
- 应用层面,核心价值在于版面连贯性要求高的长文档场景(如学术论文、企业财报),而非替代所有OCR需求。
该模型显著降低长文档解析的工程复杂度,但需注意:对小字体模糊文本或复杂手写体仍存在局限,且40页上限受32K上下文约束(团队正推进128K扩展)。对于普通用户,若仅需单页截图文字提取,传统OCR工具仍更高效;但若需处理书籍级文档且要求结构完整,Unlimited-OCR提供了当前最优的开源方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...