滑动窗口注意力是一种通过限制每个Token仅关注邻近局部窗口内上下文的稀疏注意力机制,能将计算复杂度从传统自注意力的平方级(O(n²))降至线性级别(O(n×w)),显著降低长文本处理的计算成本与显存占用,但会牺牲部分远距离语义关联的捕捉能力。平衡推理效率与模型性能,尤其适用于需处理长上下文且对实时性要求较高的场景。
滑动窗口注意力定义与技术原理
1. 基本定义
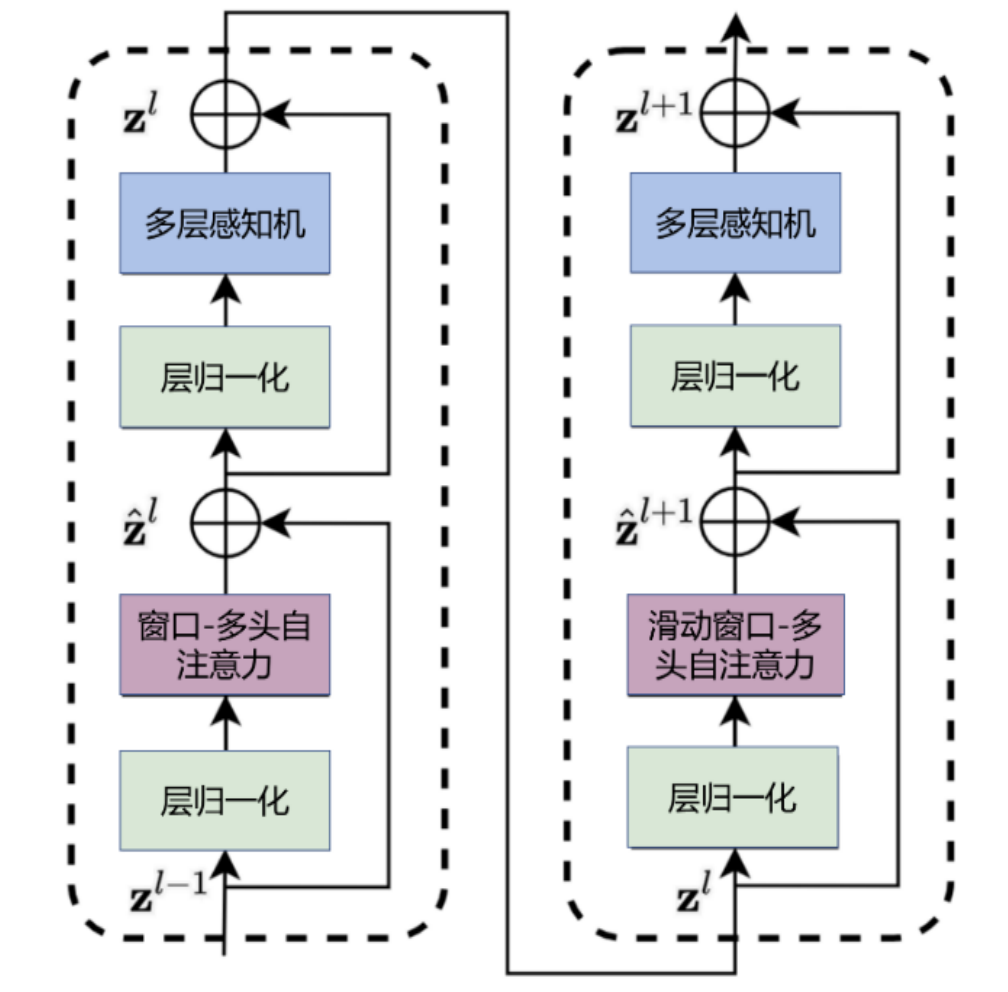
滑动窗口注意力(Sliding Window Attention, SWA)是一种稀疏注意力变体,其核心规则是:每个Token仅能关注序列中与其相邻的固定窗口大小(w)内的其他Token。例如,当窗口大小设为128时,第i个Token只能与[i-64, i+64]范围内的Token计算注意力权重,超出此范围的Token被强制忽略。
2. 技术实现原理
- 计算复杂度优化:
传统自注意力需计算所有Token对的关联(O(n²)),而SWA将每步计算量压缩至O(n×w)。当窗口大小w远小于序列总长度n(如w=128, n=8192)时,计算量可降低98%以上。 - 窗口滑动机制:
窗口随Token位置动态滑动,确保每个Token的局部上下文覆盖范围一致。例如,在序列长度为1000、窗口大小为200时,第500个Token的注意力范围为[400, 600],第800个Token的范围则为[700, 900]。 - 与全局注意力的混合设计:
为弥补远距离依赖缺失,实际应用中常采用混合架构(如1:7比例的全局-滑动窗口组合):关键层(如输入/输出层)保留全局注意力,其余层使用SWA,在维持模型容量的同时大幅削减计算开销。
滑动窗口注意力核心特点
1. 显著优势
- 推理效率大幅提升:
KV缓存显存占用降低至传统模型的1/6以下,支持单卡处理8K-16K甚至更长上下文,推理速度提升2-3倍。 - 硬件友好性:
窗口内计算保持规则稠密矩阵操作,可高效利用GPU的并行计算能力,避免不规则稀疏计算导致的硬件空转。 - 长文本实用性:
使法律合同分析、医疗病历处理等需万级Token上下文的任务从理论可行变为实际落地。
2. 固有局限
- 语义断层风险:超出窗口的关键信息会被彻底忽略,例如分析小说时无法关联开头人物设定与结尾结局。
- 长距离依赖失效:对逻辑强依赖远距离上下文的任务(如复杂数学证明、跨段落指代消解)性能明显下降。
- 窗口大小敏感:窗口过小导致信息丢失,过大则削弱效率优势,需针对任务类型精细调优(如代码生成常用512,法律文本需2048+)。
滑动窗口注意力功能与应用场景
1. 核心功能
- 长上下文高效处理:
将百万级Token的推理成本压缩至普通云服务可承受范围,使长文档摘要、整书续写等任务具备商业化可行性。 - 实时交互性能保障:
在对话系统中维持低延迟响应,避免因上下文增长导致的响应速度断崖式下降。 - 资源成本控制:
API调用成本可降低85%-90%,显著降低开发者部署门槛。
2. 适用场景
- 中长文本实时处理:
客服对话系统、新闻摘要生成、代码自动补全等需平衡速度与上下文长度的场景。 - 边缘设备部署:
手机端AI应用、IoT设备等算力受限环境,依赖SWA实现本地化长文本推理。 - 成本敏感型服务:
企业级API服务(如文档分析、合同审核)需严格控制单次调用成本的场景。
滑动窗口注意力适用人群
1. 开发者与技术团队
- 需优化推理成本的模型部署者:
当面临长上下文导致的显存溢出或高延迟问题时,SWA是性价比最高的工程化解决方案。 - 资源受限场景的算法工程师:
在移动端、嵌入式设备开发中,必须优先考虑计算效率的团队。
2. 业务决策者
- 关注落地成本的产品经理:
需评估长文本功能商业化可行性时,SWA能直接决定服务定价与用户规模上限。 - 企业级AI解决方案采购方:
在选择大模型服务商时,应验证其是否支持动态窗口调整以适配自身业务文本长度分布。
最后概况一下
滑动窗口注意力是大模型落地长文本场景的必备技术,其本质是通过牺牲部分全局语义关联能力换取计算效率的飞跃。对于80%以上的中长文本任务(<8K Token),合理配置的SWA方案在性能损失可控(通常<5%)的前提下,能实现推理成本与速度的量级突破。若任务涉及强跨段落逻辑(如法律论证),则需结合全局注意力或稀疏注意力混合架构补足短板。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...