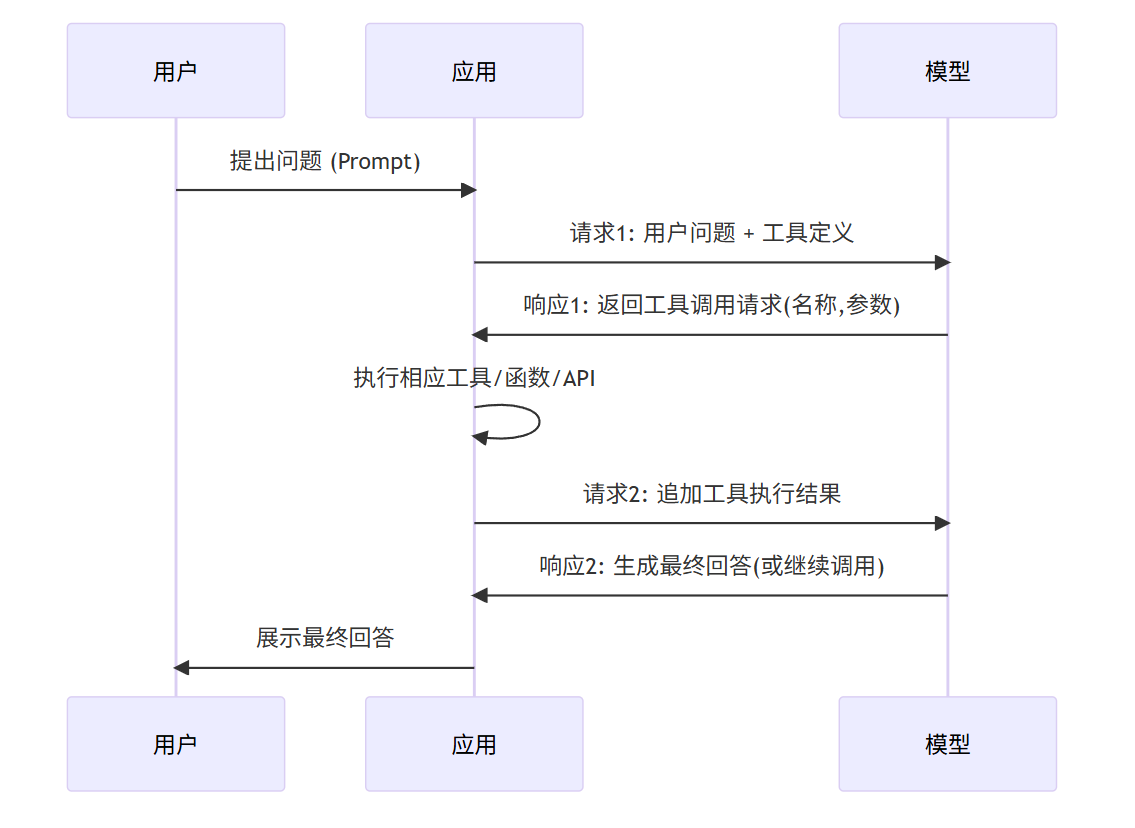
多模态大语言模型(Multimodal Large Language Models)是人工智能领域的一场深刻变革。它不再局限于处理单一的文本信息,而是像人类一样,能够同时“看”图、“听”声音、“读”文字,甚至理解视频中的时序逻辑,从而实现更全面、更智能的交互与内容生成。
这不仅仅是功能的叠加,更是从底层架构上对信息处理方式的统一与重构。
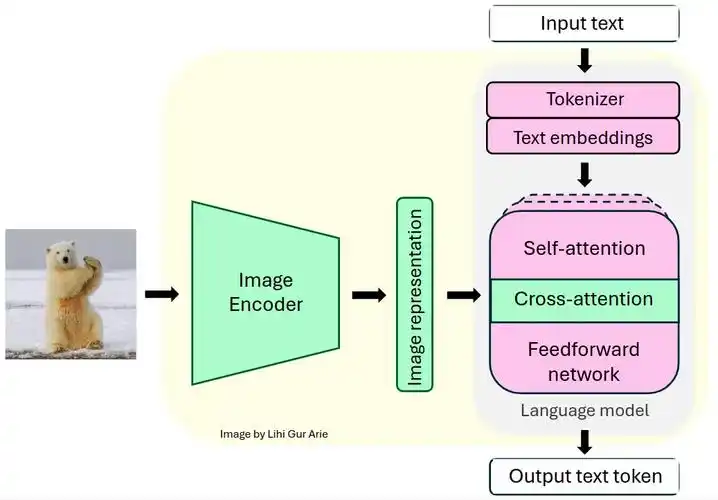
核心技术架构演进
多模态大模型的发展,本质上是从“拼接”走向“原生统一”的过程。
- 早期“拼接式”融合
早期的多模态模型,通常是“文本模型+视觉编码器”的组合。例如,先用一个独立的视觉模型(如CLIP)将图片编码成向量,再“喂”给一个大语言模型进行处理。这种方式就像“先看再写”,模型对图像的理解是间接的,信息在传递过程中会有损耗。 - 代表技术:OpenAI的GPT-6采用的Symphony架构,实现了文本、图像、音频、视频、3D五大模态的底层统一编码。阿里云的Qwen3.5-Omni也采用了端到端的原生全模态架构,能同时处理四种模态输入。
- 优势:模型能真正理解不同模态间的深层关联。例如,它能直接理解一段视频中人物的动作、对话和情绪,并生成连贯的解说文案,而不仅仅是描述画面内容。
- 前沿“自回归统一”范式
这是更具前瞻性的探索。智源研究院的Emu3模型证明了,仅用“预测下一个词元(Next-token prediction)”这一种方法,就能统一文本、图像和视频的学习与生成。
当前发展趋势
多模态大模型正朝着更深度的理解、更高效的生成和更广阔的应用领域快速演进。
- 从“看图说话”到“三维空间思考”
模型的理解能力正在从二维平面向三维空间拓展。例如,清华大学与美团联合推出的3DThinker技术,旨在解决模型在三维空间理解上的不足,让AI不仅能识别图中的物体,还能推断其空间结构和关系,这对于机器人、自动驾驶等领域至关重要。 - 超长上下文与全模态处理
模型处理信息的能力边界被不断拓宽。- 超长上下文:GPT-6的上下文窗口高达200万Token,Qwen3.5-Omni也达到了256K Token。这意味着你可以一次性输入一整本技术手册、数小时的会议录像或完整的代码库,模型都能进行分析和总结。
- 全模态生成:以Qwen3.5-Omni为例,其Thinker-Talker双轨架构,不仅能处理超长上下文,还能直接生成自然流畅的语音,无需依赖外部TTS服务,实现了真正的端到端音视频交互。
- 垂直领域的专业化应用
通用能力正迅速向专业领域渗透,解决特定行业的痛点。- 影视配音:通义实验室发布的Fun-CineForge模型,通过引入“时间模态”,解决了AI配音中长期存在的口型不同步、情感表达缺失等问题,能实现影视级的专业配音。
- 气象预测:中国科学院自动化研究所提出的MeteorPred模型,能够直接接收4D气象数据,实现对极端天气的精准预测,为构建“AI气象台”迈出了关键一步。
主流模型与应用场景
当前,国内外科技公司和研究机构都推出了各自的多模态大模型,它们在能力和定位上各有侧重。
表格
| 模型/平台 | 核心优势 | 典型应用场景 |
|---|---|---|
| GPT-6 (OpenAI) | 原生多模态架构、200万超长上下文 | 复杂视频理解、海量文档分析、跨模态内容创作 |
| Qwen3.5-Omni (阿里) | 端到端全模态、原生语音生成、Vibe Coding | 智能客服、视频会议纪要、看图编程 |
| Gemini 3.1 Pro (Google) | 原生多模态、百万级上下文 | 图文分析、长视频理解、多模态检索 |
| Emu3 (智源) | 自回归统一范式、统一生成与感知 | 前沿AGI研究、机器人操作、多模态交错生成 |
如何选择适合的模型
选择多模态大模型时,关键在于明确你的核心需求:
- 追求极致的综合能力与超长上下文
如果你需要处理极其复杂的任务,例如分析数小时的会议录像或海量的技术文档,GPT-6凭借其200万Token的上下文窗口和强大的综合性能,是首选。 - 需要端到端的音视频交互或中文场景
如果你的应用涉及智能客服、实时翻译或需要强大的中文理解能力,Qwen3.5-Omni的原生语音生成能力和对中文场景的深度优化,使其更具优势。 - 专注于特定专业领域对于影视后期、气象预测等垂直行业,应优先考虑像Fun-CineForge或MeteorPred这样针对特定任务深度优化的专业模型,它们能提供通用模型无法比拟的精度和效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...