
稀疏混合专家(Sparse Mixture of Experts, Sparse MoE)架构是当前大模型实现“参数规模扩展”与“推理成本控制”平衡的关键技术。
简单来说,它通过“分而治之”的策略,构建了一个拥有海量知识(总参数量巨大)但在处理具体任务时反应敏捷(激活参数量少)的智能系统。目前,包括 Mixtral 8x7B、GPT-4(据信)、Qwen3.6以及Skywork-MoE在内的众多前沿模型都采用了这一架构。
核心原理:条件计算与稀疏性
传统的“稠密”(Dense)模型在处理每一个输入时,都会激活所有的参数。而稀疏MoE架构基于条件计算(Conditional Computation)原则:
- 海量专家库:模型内部包含多个(例如 8 个、16 个甚至 256 个)独立的“专家”子网络。
- 动态路由:对于每一个输入(如一个词元),一个轻量级的门控网络(Gating Network/Router)会动态判断该输入属于哪个领域,并只选择最擅长处理该输入的Top-K 个专家(通常 K=1 或 2)进行计算。
- 稀疏激活:其余未被选中的专家保持“沉默”,不参与计算。
结果:模型虽然拥有千亿甚至万亿级的总参数,但每次推理的计算量(FLOPs)仅相当于一个小得多的稠密模型。
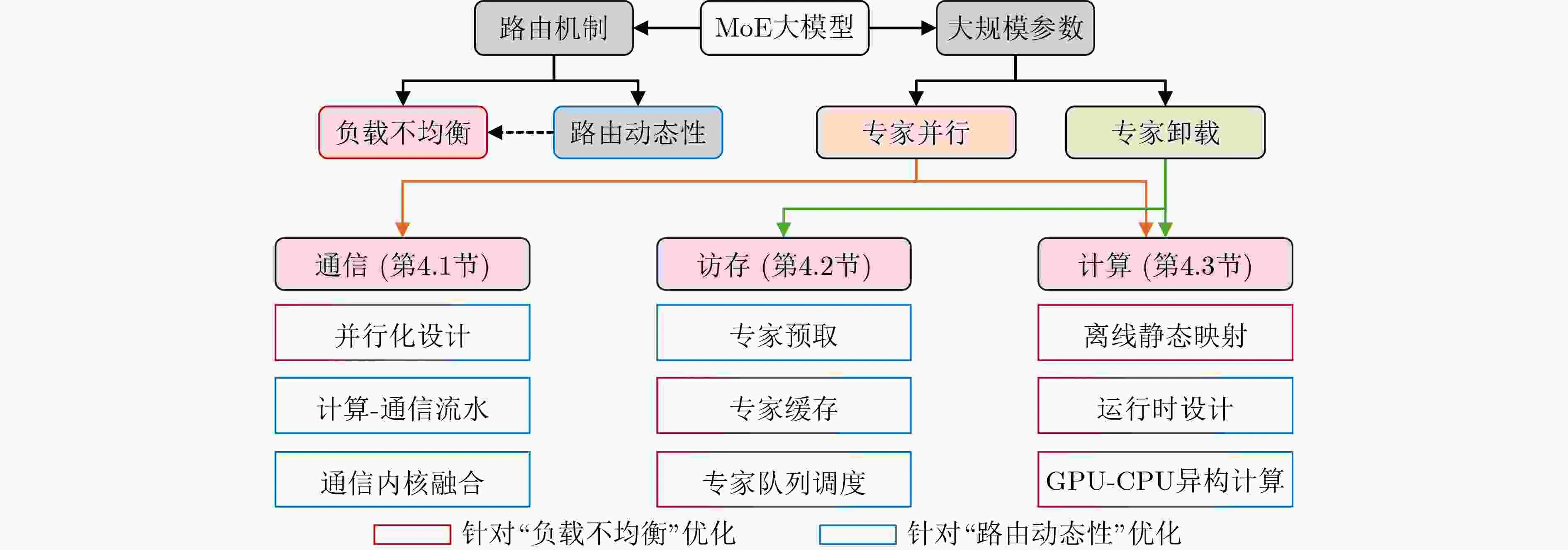
架构三大组件
一个标准的稀疏MoE层通常由以下三个部分组成:
- 专家网络(Experts)
- 通常是独立的前馈神经网络。
- 在训练过程中,不同的专家会自动“分化”,有的擅长语法,有的擅长代码,有的擅长特定领域的知识。
- 门控网络/路由器(Gating Network / Router)
- 这是MoE的“大脑”。它接收输入,计算每个专家的匹配分数,并输出一个概率分布。
- 它决定了数据流向哪里。
- 输出合并(Output Combination)
- 被选中的专家处理完输入后,其输出会根据路由器给出的权重进行加权求和,形成最终结果。
稀疏 MoE vs. 稠密模型
表格
| 特性 | 稀疏MoE架构 | 传统稠密架构 |
|---|---|---|
| 参数利用 | 动态稀疏:仅激活少量专家(如 2/16),计算量小 | 全量激活:所有参数参与计算,计算量大 |
| 模型容量 | 极大:可轻松扩展至万亿参数,存储更多知识 | 受限:参数增加会导致推理速度线性下降 |
| 推理速度 | 快:速度取决于“激活参数量”而非“总参数量” | 慢:随模型规模增大而变慢 |
| 显存占用 | 高:需加载所有专家权重到显存(带宽是瓶颈) | 中:仅需加载当前模型权重 |
| 训练难度 | 难:需解决负载不均衡问题 | 易:训练流程成熟稳定 |
关键挑战与优化
稀疏MoE并非完美,它在工程实现上面临几个核心挑战,这也是当前技术演进的重点:
- 负载均衡(Load Balancing)
- 问题:路由器可能会“偷懒”,总是把任务分配给那几个表现好的“热门专家”,导致其他专家得不到训练(即“专家坍塌”)。
- 解决:引入辅助损失(Auxiliary Loss)或无损耗均衡(Loss-Free Balancing)技术,强制路由器均匀地分配任务,确保所有专家都能得到锻炼。
- 通信瓶颈
- 问题:在分布式训练中,数据需要在不同设备上的专家之间频繁传输,通信开销巨大。
- 解决:采用混合并行策略(如专家数据并行 EDP)和优化通信算法。
- 高稀疏度设计
- 趋势:为了进一步降低计算成本,最新的架构(如蚂蚁集团的 Ling-2.0)正在追求更高的稀疏度。例如配置 256 个专家,但每次仅激活 8 个(激活率约 3.5%),以实现“推理优先”的设计目标。
典型应用案例
- Mixtral 8x7B:开源界的里程碑,证明了MoE可以在消费级硬件上运行(通过量化),且性能超越同规模稠密模型。
- Skywork-MoE:昆仑万维开源的模型,采用了MoE Upcycling技术,从较小的稠密模型扩展而来,显著降低了训练成本。
- Qwen3.6:阿里云最新推出的系列,利用稀疏激活显著降低了推理成本,同时支持多规格部署。
- 星火 X2:科大讯飞发布的模型,采用293B参数的MoE稀疏架构,结合国产算力进行了深度优化。
概况来说,稀疏混合专家架构通过“用空间换时间”(用更大的显存占用换取更快的推理速度)和“术业有专攻”(专家分工),成为了当前构建万亿参数大模型的主流路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...