
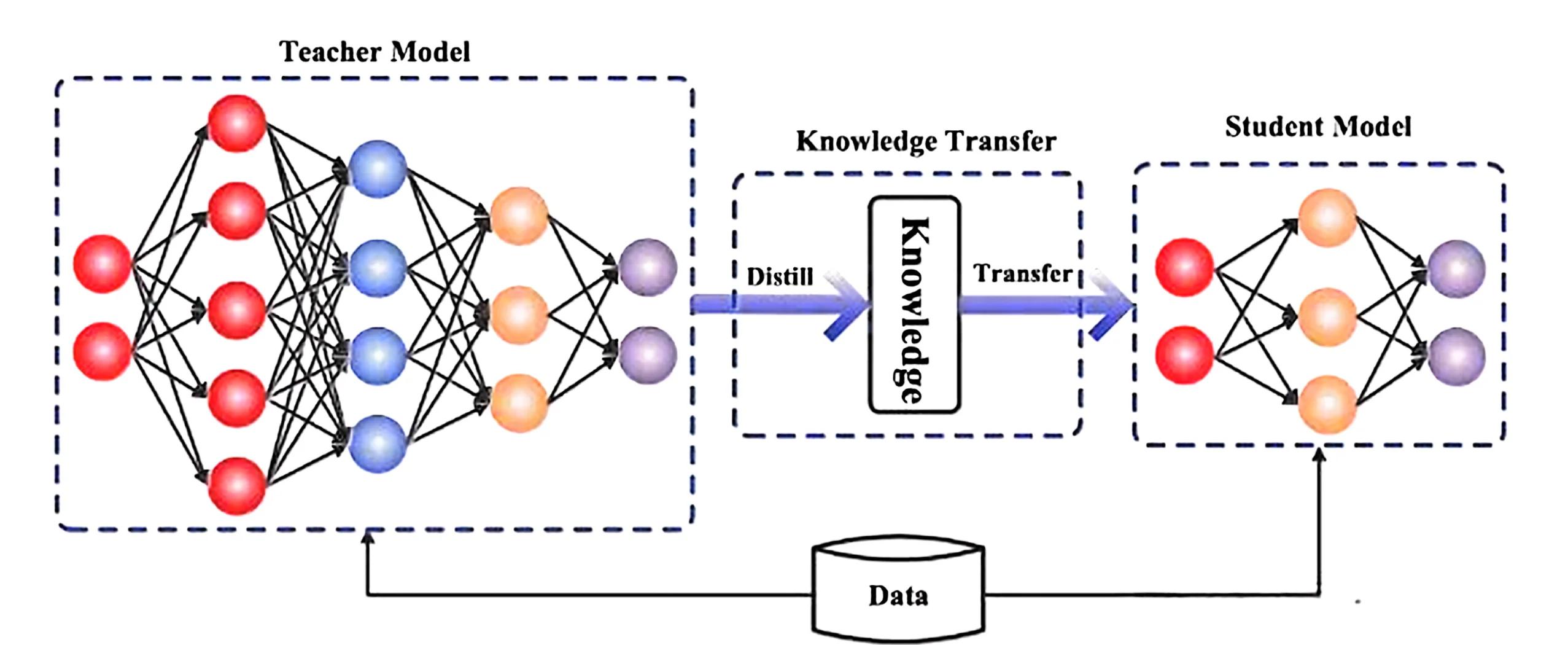
AI蒸馏(AI Distillation),也被称为知识蒸馏(Knowledge Distillation),是一种将庞大、复杂的“教师模型”中的知识,迁移到一个更小、更高效的“学生模型”中的技术。
简单来说,它的核心目的就是“以大教小”,让小模型在保留大模型绝大部分能力的同时,实现体积大幅缩小、运行速度极快、部署成本极低。如果把大模型比作一位学识渊博但行动缓慢的“老教授”,那么经过蒸馏的小模型,就是一个身轻如燕、反应极快且继承了教授全部功力的“青年高手”。
AI蒸馏核心原理
AI蒸馏的本质不是简单粗暴地压缩模型体积,而是知识的提炼与传承。其核心逻辑完全可以用人类的学习过程来类比:
1. 教师模型(Teacher Model):提供“软知识”
大模型在训练完成后,面对一个输入(比如一张猫的图片),它输出的不仅仅是一个冷冰冰的最终答案(“这是猫”),还会输出一个概率分布。
- 硬标签(Hard Label):传统训练只告诉模型“这是猫(1),不是狗(0),不是鸟(0)”。
- 软标签(Soft Label):教师模型会输出类似“猫 0.9,狐狸 0.07,狗 0.02”的概率。这些细微的概率(比如猫和狐狸的概率都相对较高)藏着大模型学到的深层逻辑和类别间的相似性关系,这些被称为“暗知识”(Dark Knowledge)。
2. 学生模型(Student Model):模仿学习
小模型(学生)不再去死记硬背海量的原始数据,而是直接去模仿大模型(老师)的“思维方式”。它努力让自己的输出概率分布去贴近教师模型的软标签。通过这种方式,小模型跳过了“苦读海量书籍”的过程,直接掌握了核心能力。
3. 温度参数(Temperature, T):控制知识浓度
为了让小模型更好地学习这些“暗知识”,蒸馏过程中引入了一个温度参数(T)。
- 当温度 T 较高时,教师模型输出的概率分布会变得更平滑,类别之间的细微差异被放大(比如原本极低的概率会被稍微拉高)。这能让学生模型更清晰地看到各类别之间的关联结构,从而学到更丰富的知识。
4. 损失函数:双向对齐
在训练时,学生模型的总损失函数通常由两部分组成:
- 硬目标损失:学生模型预测结果与真实标签的差距(保证基础准确性)。
- 蒸馏损失:学生模型输出分布与教师模型软标签分布的差距(通常用 KL散度 来衡量,保证学到了老师的“神韵”)。
AI蒸馏进阶:蒸馏不只看“最终答案”
随着技术的发展,AI蒸馏已经从最初的只看最终输出,进化到了更深层的维度:
- 输出蒸馏:最基础的方式,学生模仿老师的最终概率分布。
- 特征蒸馏:学生不仅模仿老师的最终答案,还要模仿老师大脑“中间层”的特征图或注意力权重。这就像学徒不仅要看师傅做出的成品,还要学习师傅在制作过程中的关键手法和心法。
- 关系蒸馏:让学生学习不同样本之间的相似性结构关系,进一步增强泛化能力。
为什么现在急需AI蒸馏?
在大模型(如GPT-4、Qwen等)参数量动辄千亿、万亿的今天,蒸馏技术显得尤为重要:
- 解决“重”的问题:大模型动辄几十GB,手机、手表、车载系统等普通设备根本装不下。蒸馏可以将模型压缩到几百MB甚至更小。
- 解决“慢”的问题:大模型推理一次可能需要好几秒,无法满足实时语音、实时交互的需求。蒸馏后的模型速度可以提升几十倍甚至上百倍,实现毫秒级响应。
- 解决“贵”的问题:运行大模型需要昂贵的显卡集群。蒸馏后的小模型在普通CPU甚至嵌入式芯片上就能跑,让AI从昂贵的云端服务变成了人人可用的本地能力。
🆚 AI蒸馏 vs 传统模型压缩
很多人容易把蒸馏和剪枝、量化等传统压缩技术混淆,其实它们有本质区别:
表格
| 技术类型 | 核心原理 | 形象比喻 |
|---|---|---|
| 传统压缩(剪枝/量化) | 对大模型直接裁剪参数或降低数值精度,强行缩小体积。 | 把一件厚重的棉袄强行压缩成一小团,虽然小了,但保暖性可能会下降。 |
| AI蒸馏 | 重新训练一个小模型,让它学习大模型的知识分布与推理逻辑。 | 按照棉袄的保暖配方,重新织一件轻薄又保暖的冲锋衣,又小又暖又好用。 |
目前,AI蒸馏已经成为连接前沿大模型能力与实际产业应用(如手机端的智能助手、自动驾驶的实时决策等)的关键桥梁。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...