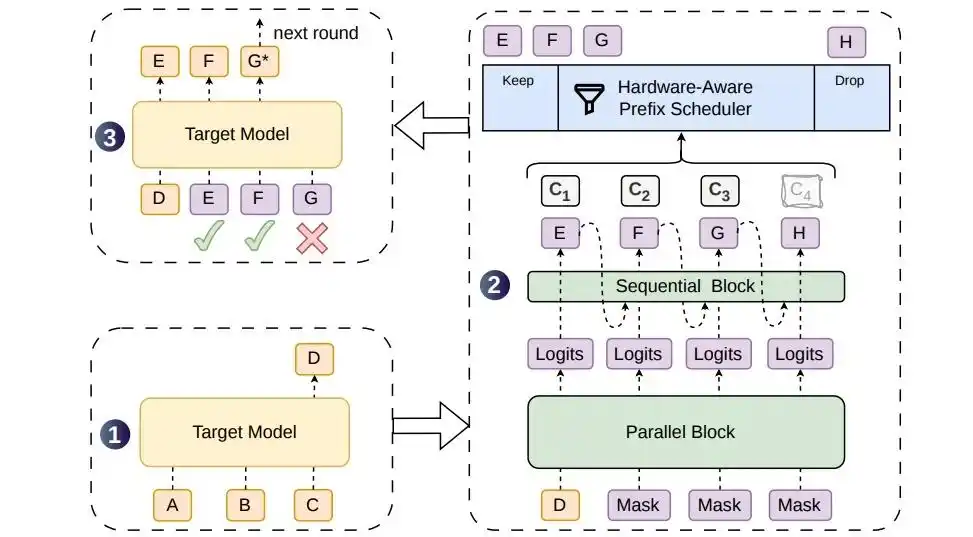
Qwen-Image-Bench是阿里云通义千问团队推出的文生图专用评测基准,主打创作者视角与专业标准。含1000 个中英双语 prompt,从画质、美学、图文对齐、真实保真、创作生成 5 大维度,设 23 项子能力与 56 条量化标准。配套Q-Judger打分模型(基于Qwen3.6-27B),自动输出细粒度评分。数据集、评测代码与模型全开源,用于客观对比文生图模型、指导选型与学术评测,填补了专业创作级能力评估的空白。
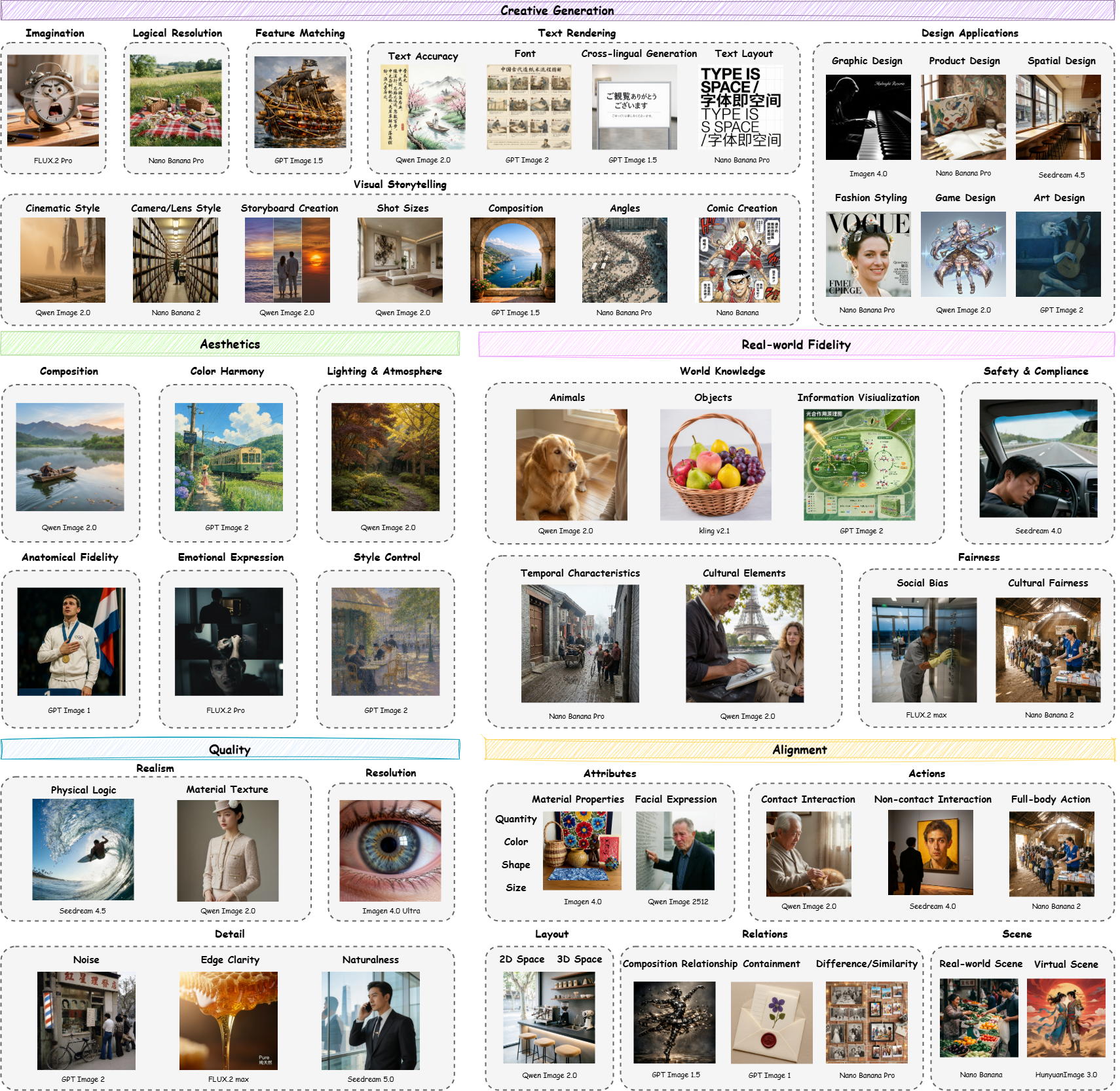
Qwen-Image-Bench核心优势
- 创作导向,贴近真实生产
与专业艺术家联合设计,从 “生成质量” 升级到 “创作能力” 评估,覆盖商业设计、视觉叙事等真实场景。
- 五层立体评估体系
- 一级:质量、美学、图文一致性、真实世界保真度、创意生成
- 二级:23 项子能力(如文本渲染、逻辑合理性、风格适配)
- 三级:56 条可量化评分标准
- 双语 + 长文本精准评测
1000 条分层双语提示(中英混合、长短覆盖),每条测试≥4 项细粒度能力,重点强化中文文本渲染与复杂排版评估。
- 专业评委 + AI 裁判双重保障
- 80 位艺术院校标注员盲测 + 三轮复核
- 自研 **Q-Judger(Qwen3.6-27B)** 自动打分,输出 JSON 结构化结果,可复现、可对比
- 区分度强,能精准定位 SOTA
传统基准难分顶尖模型,该基准可清晰拉开Qwen-Image、GPT Image 1、FLUX.1等差距,尤其在中文文本、创意设计、真实场景维度。
Qwen-Image-Bench核心特点
- 层级化评估树:从整体到细节,覆盖 “构图→元素→细节→文字→创意” 全链路。
- 创作能力专项:新增想象力、特征匹配、逻辑解析、文本渲染、设计应用、视觉叙事六大创作维度。
- 商业级文本渲染评测:支持多行排版、段落语义、中英混排、字体 / 布局 / 准确性细项打分。
- 开放透明:数据集、Q-Judger 模型、评测代码全开源。
- 轻量可落地:单卡可跑,支持批量评测与自定义提示集。
Qwen-Image-Bench核心功能
- 文生图模型标准化评测
对任意 T2I 模型输出5 维度总分 + 23 项子分 + 56 条明细,自动生成对比报告。
- 文本渲染专项测评
精准评估中文 / 英文 / 混排、多行、段落、字体、布局、可读性,量化到像素级错误。
- 创意设计能力打分
覆盖平面设计、产品设计、空间设计、时尚造型、游戏美术、视觉叙事等商业场景。
- 模型对比与选型
横向对比主流模型,输出雷达图 + 排名 + 弱点分析,助力企业选型。
- 自定义评估任务
支持导入私有提示集、调整权重、定制评分规则,适配垂直场景(如电商、教育、营销)。
Qwen-Image-Bench应用场景
- AI 模型研发:训练阶段快速验证迭代效果,定位文本渲染 / 构图 / 逻辑短板。
- 企业选型采购:对比 Qwen-Image、GPT Image 1、FLUX.1 等,选择中文 / 双语、商业设计、长文本最优模型。
- 内容生产质检:电商主图、海报、PPT、绘本、多语言营销素材的批量质量审核。
- 学术研究:提供统一、可复现的评测标准,支撑文生图领域顶会论文实验。
- 教育与科普:生成教学插图、知识图谱、双语课件,评估准确性 + 可读性 + 美观度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...