
DSpark是北京大学与DeepSeek联合开发的开源大语言模型推理加速框架,通过创新的半自回归生成与置信度调度技术,在高并发场景下将生成速度提升60%至85%,同时显著降低推理成本。其核心突破在于解决大模型自回归生成导致的延迟问题,无需牺牲生成质量即可实现高效推理,目前已部署于DeepSeek-V4系列模型的生产环境。
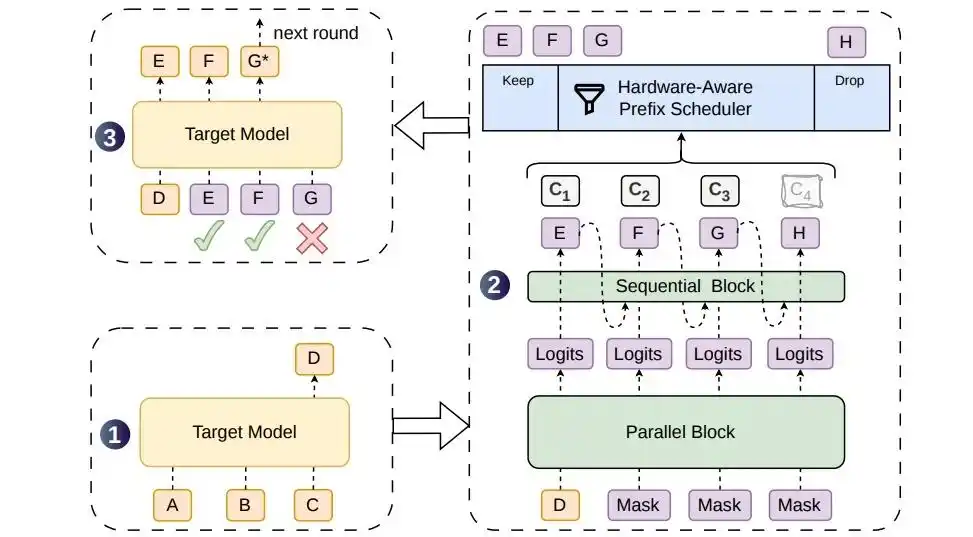
DSpark技术原理
1. 半自回归候选生成机制
- 并行主干+轻量级顺序模块:
DSpark采用半自回归架构,先由并行主干网络(基于DFlash改进)一次性生成全部候选token的隐藏状态和基础logits,再通过轻量级顺序模块逐token注入前缀依赖信息。该模块提供两种实现:
- 马尔可夫头:仅依赖前一个token,计算开销极低。
- RNN头:通过循环状态累积完整前缀信息,提升长序列依赖建模能力。
实验证明,仅需两层Transformer深度的DSpark即可超过五层DFlash的接受长度,参数效率显著优化。
2. 置信度调度验证机制
- 动态置信度预测与校准:
模型在每个候选位置输出置信度分数,预测该token在给定此前所有token均被接受条件下的存活概率。训练完成后,通过逐位置温度缩放对置信度进行校准,使其与实际接受率对齐。
- 硬件感知前缀调度:
调度器将验证长度选择建模为全局吞吐量最大化问题,结合实时GPU负载与预实测吞吐量曲线,为每个请求动态分配验证长度,优先保障高存活概率token的计算资源,避免将算力浪费在高拒绝风险的尾部token上。
DSpark核心特点
1. 速度与效率突破
- 高并发吞吐量提升显著:
在DeepSeek-V4-Flash引擎上,当单用户生成速度要求≥80 token/s时,聚合吞吐量提升51%;若SLA收紧至120 token/s,吞吐量优势可达661%。
- 单用户生成速度飞跃:
在同等吞吐量下,单用户生成速度提升60%至85%,用户等待时间大幅缩短,高峰期响应更稳定。
2. 无损质量与通用性
- 严格保证生成质量:
通过拒绝采样机制确保输出分布与原始模型一致,生成质量无任何损失。
- 跨模型兼容性强:
不仅适配DeepSeek-V4系列,还在Qwen3、Gemma4等主流开源模型上验证有效,中小企业可直接迁移应用。
3. 成本优化能力
- 减少无效计算开销:
置信度调度自动筛除低存活概率的候选token,避免目标模型浪费算力验证无效内容。
- 降低推理成本:
单位请求的算力消耗显著下降,企业可将节省的算力转化为更低的API价格或更高的免费额度。
DSpark主要功能
1. 高并发场景加速
- 动态负载自适应:
系统并发数较低时,自动分配4-6个token的验证长度以充分利用空闲资源;并发上升时平滑缩减验证长度,避免资源争用导致的性能骤降。
2. 工程级系统集成
- 异步调度与稀疏注意力优化:
- 采用异步调度模式隐藏调度延迟,兼容现有系统框架。
- 通过物理执行与逻辑序列解耦,将动态变长验证前缀转化为稀疏注意力计算,避免传统填充导致的性能损耗。
3. 开源生态支持
- 完整工具链开源:
提供训练代码、评估脚本及模型检查点,支持开发者快速部署适配自身业务场景。
DSpark适用人群
1. 企业级AI服务提供方
- 需要高并发推理能力的平台:
如AI客服、批量代码生成、长文档解析等场景,可显著提升服务承载能力与用户体验。
- 成本敏感型业务:
通过降低单位请求算力消耗,直接减少云服务开支,尤其适合流量规模大的应用。
2. 开发者与研究机构
- 开源模型优化需求者:
可将DSpark迁移至Qwen、Gemma等模型,无需重新训练即可提升推理效率。
- 推理系统研究者:
其半自回归架构与置信度调度机制为推测解码领域提供了新范式。
3. 普通终端用户
- 追求流畅交互体验的用户:
使用接入DSpark的AI产品时,响应速度更快、高峰期卡顿减少。
- 低成本服务受益者:
企业节省的算力成本可能转化为更低价的付费服务或更高的免费额度。
DSpark的核心价值在于将大模型推理从“拼参数”转向“拼效率”,通过软件优化突破硬件限制,在国产算力受限的背景下为行业提供了可落地的高性能方案。其技术逻辑不依赖特定硬件,适用于任何需要平衡速度、成本与质量的生成式AI应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
为这篇文章评分
10.0/ 10
6 人评价
100%
0%
0%
0%
0%
点击⭐️进行评分
下一篇
没有更多了...
相关文章

暂无评论...