
半自回归候选生成机制是一种大语言模型推理加速技术,通过在并行生成骨干网络上叠加轻量级顺序依赖模块,兼顾推理速度与生成质量。放弃”完全自回归”或”完全非自回归”的极端方案,转而采用块内并行+块间部分依赖的混合策略,在不显著降低生成质量的前提下,将推理速度提升50%以上。
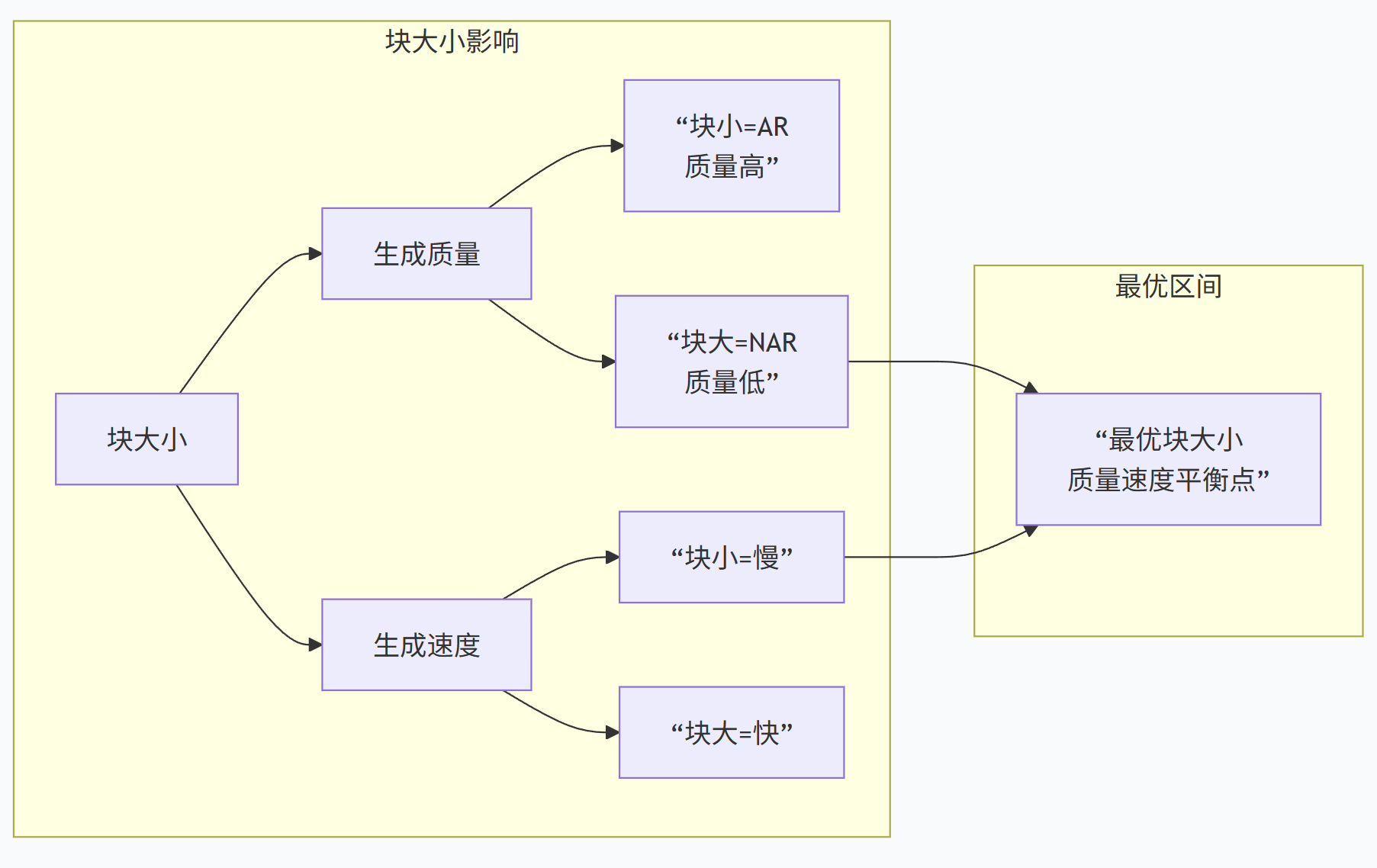
半自回归候选生成机制技术原理
1. 核心架构设计
- 并行主干网络:
一次性生成整个候选块(block)的基础特征(如32个token的隐藏状态),避免逐token串行计算的延迟。 - 轻量级顺序模块:
在并行结果基础上,仅对关键位置补充局部依赖关系(如仅依赖前1-2个token的马尔可夫头),而非完整自回归链。 - 动态块划分:
根据上下文复杂度自适应调整块大小(如简单内容用64token大块,复杂逻辑用8token小块),平衡速度与质量。
2. 关键操作流程
- 候选生成阶段:
并行网络快速输出候选token序列(”打草稿”),轻量级顺序模块仅修正块尾部的时序冲突(如避免”语义漂移”)。 - 置信度动态调度:
对每个候选token输出存活概率预测,高置信度内容直接批量放行,低置信度片段提前截断或精细验证。 - 硬件感知验证:
根据GPU显存负载动态调整验证长度,优先保障高并发场景下的系统吞吐稳定性。
半自回归候选生成机制核心特点
1. 性能优势
- 速度-质量平衡:
相比纯自回归方案(如Eagle3),接受长度提升26.7%~30.9%;相比纯并行方案(如DFlash),长序列后端token接受率显著改善。 - 硬件效率优化:
通过减少无效计算,在相同吞吐量下将单用户生成速度提升60%~85%,高并发场景吞吐量提升最高达400%。 - 跨模型通用性:
适配Qwen、Gemma等主流开源模型,无需针对特定模型重新设计架构。
2. 技术局限
- 实现复杂度高:
需精细设计顺序模块与并行网络的耦合机制,参数效率对轻量级模块深度敏感。 - 长依赖建模弱化:
对跨块的长程逻辑依赖(如前后文严密论证)支持不足,复杂推理任务仍需辅助校验。 - 训练成本增加:
需额外设计置信度校准机制,训练流程比纯自回归模型更复杂。
半自回归候选生成机制功能
1. 核心功能
- 高并发推理优化:
有效缓解服务系统在严格延迟约束下的吞吐断崖问题,维持高负载稳定性。 - 算力成本压缩:
无需堆叠硬件即可提升单机并发承载量,显著降低大模型落地门槛。 - 质量无损加速:
严格保证输出分布与原始模型一致,避免因加速导致的生成质量下降。
2. 适用场景
- 实时交互系统:
适用于高并发对话服务(如客服机器人),需在200ms内响应且维持多轮连贯性。 - 长文本生成任务:
在代码生成、报告撰写等需输出数百token的场景中,避免纯并行方案的语义断裂问题。 - 资源受限环境:
适合边缘设备或低成本GPU部署,通过减少无效计算弥补算力短板。
半自回归候选生成机制适用人群
1. 大模型服务开发者
- 推理引擎优化:
用于构建高性能推理框架(如DSpark、DeepSpec工具链),替代传统推测解码方案。 - 硬件成本控制:
通过提升单卡吞吐量降低云服务成本,尤其适合需支撑海量请求的商业API。
2. 算法研究人员
- 新型解码策略设计:
作为平衡速度与质量的基准方案,用于探索更高效的混合生成范式。 - 跨领域迁移验证:
可尝试将机制扩展至语音合成、视频生成等非文本模态任务。
3. 企业技术决策者
- 落地成本评估:
当业务需求对延迟敏感且预算有限时,优先考虑集成半自回归方案。 - 技术路线选择:
若应用场景侧重短文本交互(如聊天机器人),其优势远超纯自回归模型;但对超长逻辑链推理(如法律文书生成),需结合后处理校验模块。
半自回归候选生成机制的本质是”有选择地保留关键依赖”,通过牺牲部分长程建模能力换取显著速度提升。它特别适合对响应速度敏感、但无法接受质量明显下降的生产环境,已成为当前大模型推理加速的主流技术路径之一。实际应用中需注意:简单任务可直接采用大块并行以最大化速度,复杂任务则需缩小块尺寸并增强顺序校验,避免因过度优化导致逻辑断裂。对于开发者,建议优先使用DSpark等开源框架的预验证实现,而非从零构建。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...