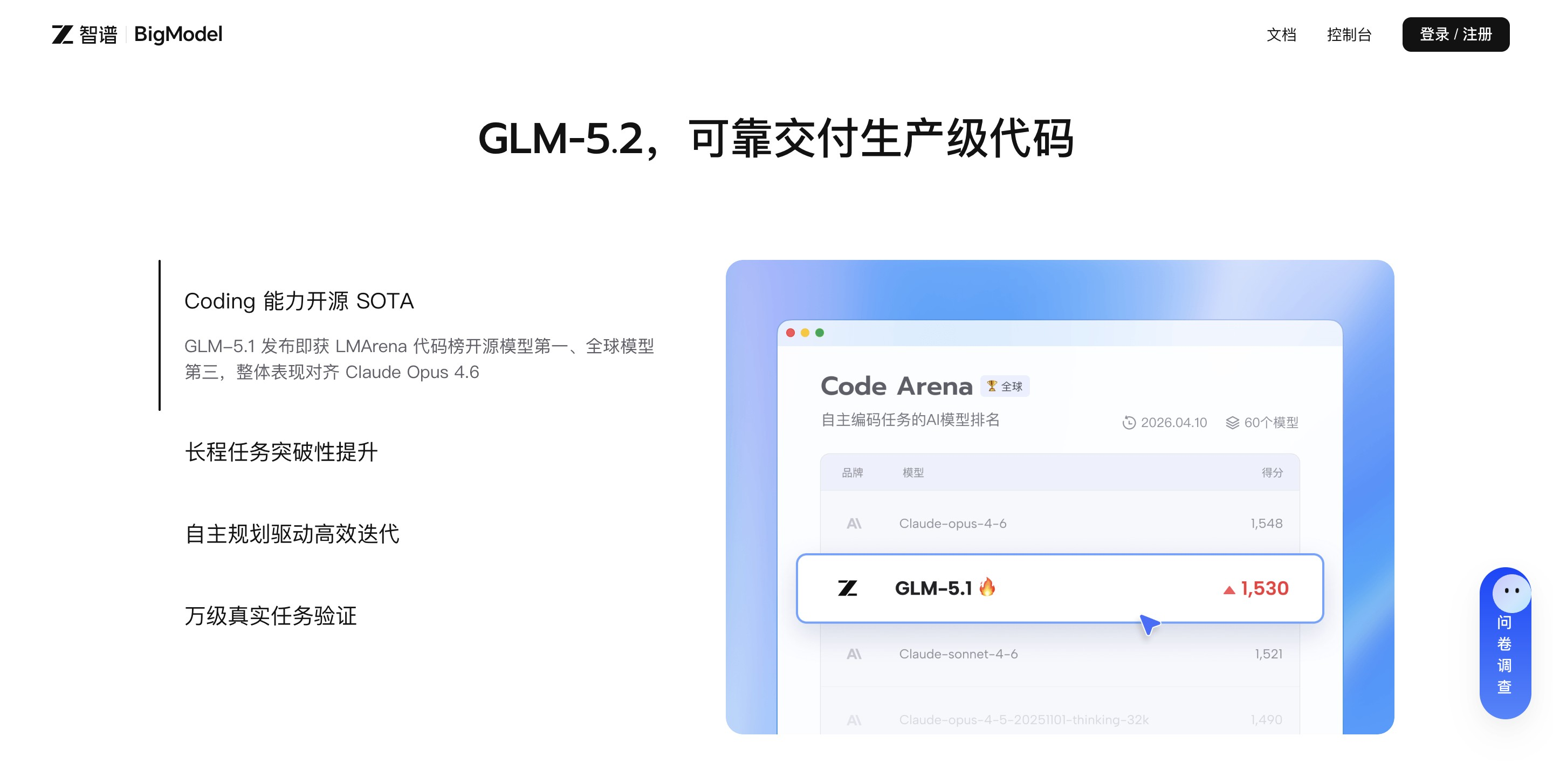
Qwen2.5-7B是阿里云通义千问系列推出的76.1亿参数开源大语言模型,核心特点为支持131.072 tokens超长上下文、原生结构化输出能力及显著提升的数学与编程性能,适用于需平衡推理成本与专业能力的中等规模场景。
其最大价值在于以中等参数量实现接近更大模型的专业任务表现,尤其适合长文本处理、多语言交互及企业级结构化数据生成需求。

Qwen2.5-7B核心定义与定位
1. 基础属性
- 参数规模:总参数量76.1亿(非嵌入参数65.3亿),属于中等规模开源模型。
- 开源协议:采用Apache 2.0许可证,允许商用、微调及私有化部署。
- 版本定位:Qwen2.5系列中兼顾性能与成本的关键型号,面向对推理速度、长文本支持及结构化输出有明确需求的场景。
2. 能力边界
- 上下文长度:输入支持131,072 tokens(约80万汉字),输出可达8,192 tokens,远超早期模型的8K–32K限制。
- 语言覆盖:支持29种以上语言,包括中、英、法、西、德、日、阿拉伯语等,中英双语任务表现尤为突出。
- 专业能力:在数学推理(MATH评测80+)、代码生成(HumanEval 85+)及知识理解(MMLU 85+)上显著优于前代模型。
Qwen2.5-7B特点
1. 超长上下文处理
- 端到端长文本理解:可一次性加载整本《红楼梦》或数百页技术文档,避免分段处理导致的语义断裂。
- 动态位置编码优化:通过NTK-aware RoPE技术解决长序列外推问题,确保131K长度下位置感知稳定性。
2. 结构化数据能力
- 原生JSON/XML输出:无需后处理即可稳定生成语法正确的结构化数据,在API响应生成任务中语法正确率达92.4%。
- 表格与代码解析:能准确理解嵌入提示词的表格、JSON配置文件,并基于其生成精准操作指令。
3. 高效推理设计
- 分组查询注意力(GQA):采用28查询头/4键值头配置,KV缓存内存占用比多头注意力降低37%,显著提升长序列推理效率。
- 轻量化架构:通过SwiGLU激活函数与RMSNorm归一化优化计算开销,在消费级GPU(如4×RTX 4090D)上即可流畅运行。
Qwen2.5-7B核心优势
1. 性能与成本平衡
- 推理效率提升:在131K上下文场景下,KV缓存内存消耗比MQA减少37%,推理延迟降低22%。
- 资源需求可控:通过4-bit量化可将模型体积从28GB压缩至4GB,适配单卡24GB显存设备(如RTX 4090),年GPU成本降低60%。
2. 垂直场景适配性
- 编程与数学强化:在代码生成任务中得分提升近18%,支持Python、Java等多语言及中等难度LeetCode题目求解。
- 多语言业务支持:中英双语场景响应质量接近原生水平,适合国际化产品开发与多语言客服系统。
3. 企业级落地能力
- 指令遵循可靠性:对system prompt的适应性显著增强,能稳定执行角色扮演、条件控制等复杂交互。
- 部署灵活性:提供Base与Instruct双版本,支持Hugging Face、vLLM、llama.cpp等多种推理框架,量化后可部署于8GB显存设备。
Qwen2.5-7B技术原理
1. 架构创新
- 两阶段预训练:先以4,096 token长度训练基础能力,再扩展至32,768 token优化长上下文表现,避免直接训练超长序列的不稳定性。
- 动态外推机制:通过ABF技术将RoPE基础频率从10,000增至1,000,000,使模型自然适应131K长度而无需额外微调。
2. 训练优化
- 高质量数据筛选:利用Qwen2-Instruct模型作为多维度数据质量过滤器,针对性增强数学、代码及专业领域数据占比。
- 合成数据增强:基于Qwen2.5-Math/Coder模型生成高可信度合成数据,并通过奖励模型严格过滤,提升垂直领域表现。
3. 推理加速技术
- 渐进式解码约束:在生成JSON等结构化内容时,动态校验括号匹配与字段格式,避免后处理纠错开销。
- 量化与内存优化:结合GPTQ/AWQ 4-bit量化与PagedAttention技术,在精度损失<2%前提下实现显存占用降低85%。
Qwen2.5-7B应用场景
1. 专业文档处理
- 法律与金融领域:对整份合同或财报进行端到端分析,提取关键条款并生成摘要,避免分段处理导致的逻辑遗漏。
- 科研文献管理:跨章节解析学术论文,自动标注研究方法、结论及数据来源,支持长篇综述生成。
2. 开发与工程支持
- 智能编程助手:根据需求生成可执行代码片段,支持多语言调试建议与错误修复,尤其适合API开发与脚本生成。
- 自动化报告系统:将数据库查询结果直接转换为结构化JSON/XML,用于动态生成业务报表或API响应。
3. 多语言业务系统
- 跨境客服平台:在中英等29+语言间无缝切换,处理用户咨询并生成符合本地化习惯的回复。
- 内容本地化工具:对技术文档进行语义级翻译与格式保留,确保代码示例、表格数据等关键元素准确传递。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
.png)

暂无评论...