MAI-Thinking-1是微软于2026年6月3日发布的首款完全自研的高级推理AI模型,采用350亿活跃参数的稀疏混合专家(MoE)架构,完全基于企业级合规数据从零训练,未使用任何第三方模型蒸馏数据。
其核心定位是以中等规模模型实现顶尖推理能力,在数学、代码和长上下文任务中达到行业领先水平,同时显著降低企业级应用的推理成本。
MAI-Thinking-1核心特点
1. 完全自研与数据合规性
- 无蒸馏训练:模型未依赖任何第三方模型的输出数据,训练数据全部来自企业级授权、清洗过的合规数据源,严格排除AI生成内容。
- 数据可追溯性:针对金融、医疗等强监管领域,提供数据来源透明度,满足企业对知识产权合规的硬性需求。
2. 性能与规模平衡
- 中等规模高效率:拥有350亿活跃参数(总参数量约1万亿),在关键任务中性能对标Claude Opus 4.6等更大模型,但推理资源占用显著低于巨型模型。
- 超长上下文支持:支持128K至256K token上下文窗口,可一次性处理约600页文档,适合长文本分析与复杂任务拆解。
3. 任务导向设计
- 专为多步骤推理优化:擅长将复杂问题拆解为可执行子任务,尤其适用于代码生成、数学证明、科学推理等需逻辑链的任务。
- 工具调用能力:可直接与外部环境交互,执行需调用API或代码解释器的智能体(Agent)级操作。
MAI-Thinking-1核心优势
1. 成本效率突破
- 推理成本大幅降低:在相同任务下,推理资源消耗比行业领先模型低5–10倍,企业实际部署时可显著减少云服务开支。
- 企业级优化案例:针对麦肯锡等客户的定制化模型,在性能超越GPT-5.5的同时实现10倍成本效率提升。
2. 技术可控性
- 全栈自主可控:从训练框架、RL优化到推理加速器,全部由微软自研技术栈支持,避免依赖第三方模型的黑箱风险。
- 安全与有用性平衡:通过强化学习同时优化输出安全性与任务完成度,减少有害内容生成。
3. 垂直场景适配
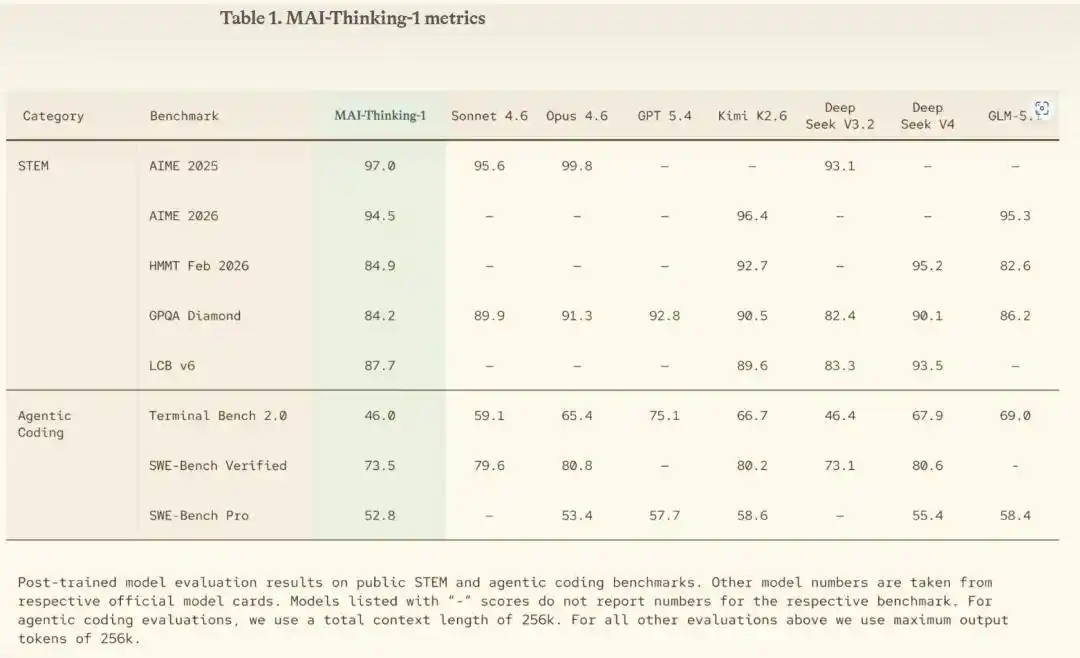
- STEM与代码能力突出:在AIME 2025数学竞赛测试中得分97.0%,SWE-Bench Pro编程基准测试达52.8%,接近Claude Opus 4.6水平。
- 盲测偏好度领先:在人类评估中,综合表现优于Claude Sonnet 4.6,尤其在逻辑严谨性与任务拆解能力上。
MAI-Thinking-1技术原理
1. 稀疏MoE架构设计
- 动态专家路由:模型总参数约1万亿,但每次推理仅激活350亿相关参数,通过78层Decoder-only Transformer结构实现高效计算。
- 5:1局部/全局注意力机制:优化长上下文处理效率,减少KV Cache内存占用。
2. 训练方法创新
- 纯原生数据训练:基于30T tokens企业级授权数据预训练,排除所有AI生成内容,确保数据纯净度。
- “爬坡机器”强化学习:通过自研RL框架从零学习推理链,不依赖先验思维链(CoT)蒸馏,针对STEM、编码等场景进行数千步持续优化。
3. 评估体系
- 近40个私有基准测试:覆盖代码、数学、通用知识等五大类任务,优先采用负对数似然(NLL)评估,避免多选题格式偏差。
- 防数据污染机制:对常见测试集进行去污染处理,确保结果真实反映模型能力。
MAI-Thinking-1应用场景
1. 企业级智能体开发
- 自动化工作流:将复杂业务流程(如合同审核、财报分析)拆解为可执行步骤,驱动自主Agent完成端到端任务。
- Copilot深度集成:作为Microsoft 365和GitHub Copilot的底层推理引擎,提升代码生成、文档总结等场景的准确性。
2. 专业领域推理
- 科学与工程计算:解决需多步推导的物理、化学问题,辅助科研人员快速验证假设。
- 金融与法律分析:处理长篇法规文档或市场报告,提取关键逻辑链并生成合规结论。
3. 开发者工具链
- SWE-Bench级代码修复:直接理解代码库上下文,定位并修复真实开发环境中的复杂Bug。
- 低延迟推理服务:通过Azure AI Foundry提供低成本API调用,适合对响应速度敏感的企业应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...