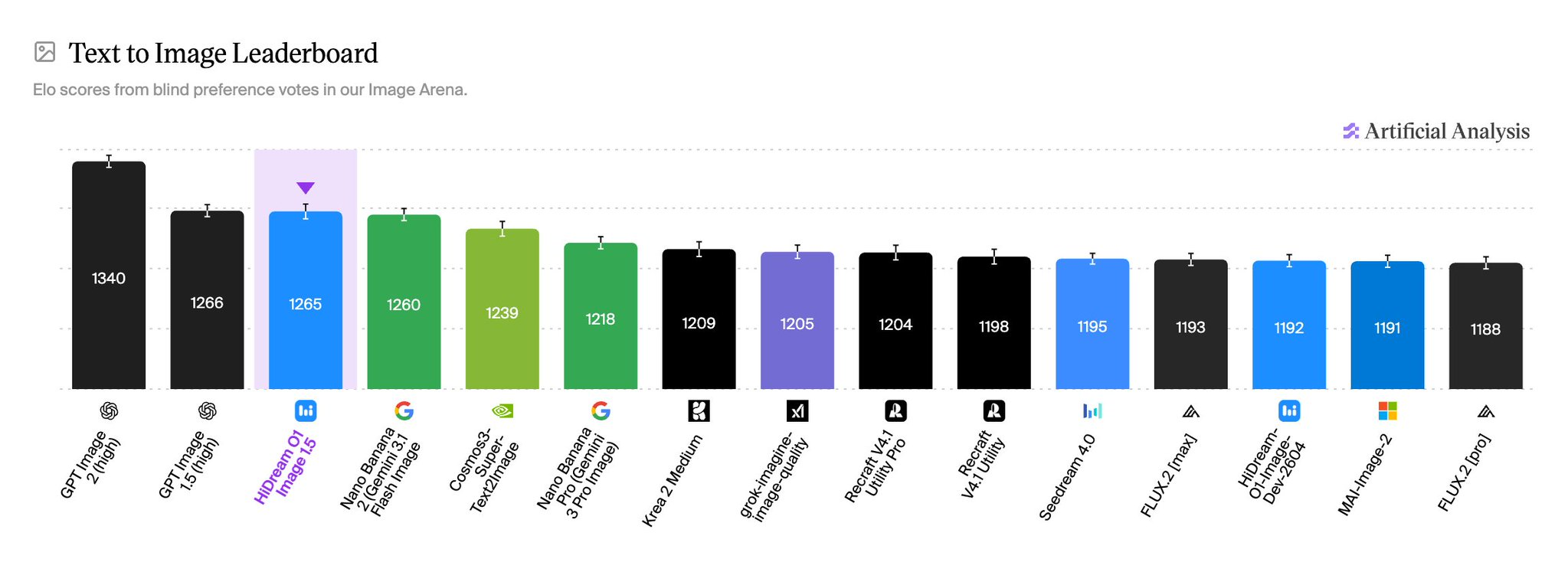
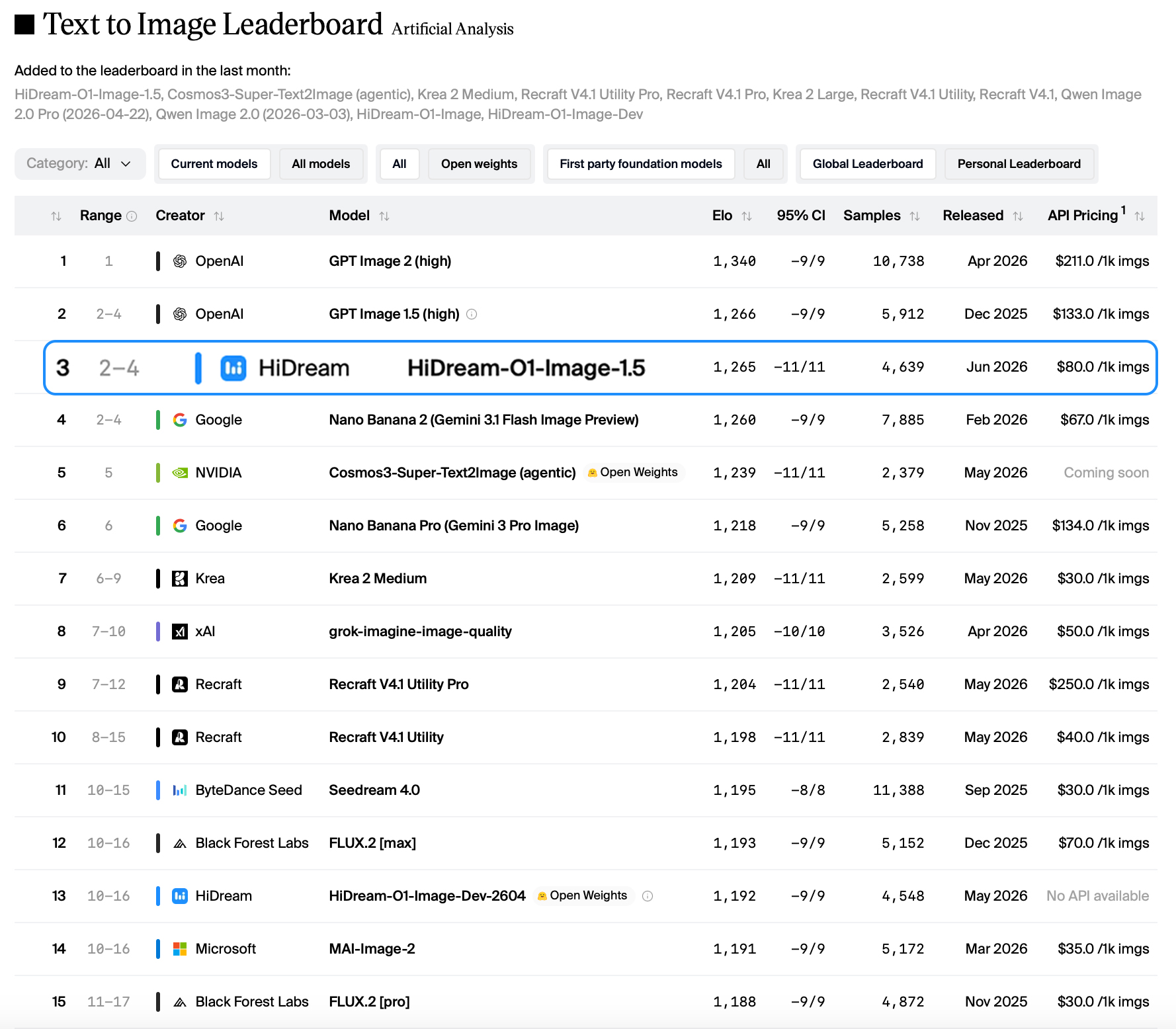
HiDream-O1-Image-1.5核心特点
1. 原生全模态架构创新
- 单一共享Token空间:将图像像素、文本Token、视频体素等原始信号直接映射至同一表征空间,由统一的Unified Transformer(UiT)完成端到端理解与生成,避免传统模块化路径中的信息转换损耗。
- 无VAE与独立文本编码器:彻底摒弃潜空间压缩环节,直接在原始像素空间进行扩散去噪,消除高频细节丢失与图文语义错位问题。
2. 商业场景强适配能力
- 复杂文字渲染:支持中英文混排、多级标题、数字公式等密集文本场景,文字可读性与排版稳定性显著优于主流模型。
- 多主体一致性控制:在4-11个复杂主体组合场景中保持角色、服饰、空间关系的逻辑统一,解决传统模型常见的属性错位问题。
- 视觉叙事能力:可生成逻辑连贯的多宫格分镜,自动维持角色形象、场景逻辑与视觉风格的一致性。
3. 高分辨率原生生成
- 2048×2048原生分辨率端到端输出:无需多阶段超分或后处理,直接生成电影级画质图像,避免压缩重建导致的色彩边界伪影。
HiDream-O1-Image-1.5技术原理
1. 像素级统一表征系统
- 跨模态直接对齐:文本Token可直接关联像素块坐标值,像素块亦能反向关注文本语义,实现底层表示空间的无缝交互。
- 任务条件零切换:通过共享Token空间内的任务标识符区分文生图、指令编辑、主体个性化等任务,无需加载LoRA或ControlNet插件。
2. 推理驱动生成机制
- Prompt Agent预解析:生成前自动启动思维链推理,深度解析空间布局、物理逻辑与文本排版需求,将模糊指令重写为高精度控制指令。
- 指令驱动编辑:支持通过
--ref_images传入参考图,结合自然语言指令实现移除物体、风格迁移等精准修改,无需额外训练。
3. 参数高效架构设计
- 8B参数实现跨量级性能:商用版HiDream-O1-Image-1.5在GenEval、HPSv3等六项基准测试中全面超越56B参数的FLUX.2等模型,参数效率提升3–7倍。
- 多任务统一权重:文生图、编辑、个性化等任务共享同一套参数,避免传统模型需切换不同模块的冗余计算。
HiDream-O1-Image-1.5关键优势
1. 生产级交付能力
- 电商海报场景:可自然融合商品、多层级营销文案与复杂版式,中英文混排错误率低于3%,满足品牌视觉传播的商用标准。
- IP形象设计:围绕同一角色生成多角度视图时,五官、服饰一致性达95%以上,显著提升角色三视图开发效率。
- 影视分镜生成:在连续画面中稳定维持角色动作逻辑与场景连贯性,支持从创意到分镜的快速视觉化。
2. 真实性与细节控制
- 人像摄影级表现:在皮肤质感、服饰纹理、肢体互动等细节上规避AI常见油腻感,广角/低机位等复杂构图仍保持透视协调。
- 自然环境精准建模:对雪山湖泊、沙漠驼队等大场景的空间层次与光影变化还原度达电影质感,适配旅游宣传与游戏场景设计。
3. 工作流价值升级
- 降低专业门槛:通过预解析机制减少用户对提示词工程的依赖,普通创作者也能生成高质量商业图像。
- 多模态扩展基础:为后续视频首帧生成、长视频连贯性控制提供稳定底层能力,推动图像生成向世界模型演进。
HiDream-O1-Image-1.5应用场景
1. 商业营销领域
- 电商视觉生产:快速生成带完整营销文案的商品海报,适配直播带货、社媒种草等高频需求,文字与商品融合度显著提升。
- 品牌IP开发:围绕核心角色生成多视角形象图,同步输出三视图与情绪表情库,加速吉祥物设计与衍生品开发。
2. 影视与内容创作
- 分镜脚本可视化:将文字剧本一键转为逻辑连贯的多宫格分镜,保持角色形象与场景逻辑统一,缩短影视前期制作周期。
- 短漫剧素材生成:为动漫、教育类内容提供高一致性角色与背景图,已累计支撑超5000分钟短漫剧制作。
3. 跨模态协同场景
- 图文一体化设计:在计划书、数据看板等场景中自然嵌入文字信息,兼顾排版秩序与视觉美感。
- 多语言本地化适配:针对海外市场生成符合文化习惯的视觉内容,中英文混排场景错误率低于主流模型50%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...