
MiMo-V2.5-ASR是小米开源的语音识别模型,作为全链路语音交互系统的听觉基座,复杂真实场景下的高鲁棒性语音转写。它无需预设语种标签即可精准处理中英混说、方言交织、强噪音干扰等环境,在多人会议、专业内容转录等任务中错误率低于12%,且原生支持标点符号生成,转写结果可直接用于内容生产。
MiMo-V2.5-ASR核心特点
1. 复杂场景适应能力
- 方言与Code-Switch无缝识别:支持吴语、粤语、闽南语、四川话等8种中文方言,并能自动识别中英混说切换点(如“这个function需要debug”),无需预先标注语种。
- 强噪音鲁棒性:在信噪比低至-5dB的嘈杂环境(如街道、会议室)中仍保持89%以上的识别准确率。
- 多说话人分离:精准区分交叉对话中的不同发言者,适用于会议记录、法庭庭审等多人场景。
2. 专业内容精准解析
- 高知识密度内容识别:对古诗词、医学术语、人名地名等专业词汇的识别准确率达94.7%,显著优于通用模型。
- 歌曲与歌词分离:在伴奏与人声混合场景下,歌词识别错误率低于5%,可过滤背景音乐干扰。
3. 开箱即用的生产级设计
- 原生标点生成:结合语音停顿与语义逻辑自动插入标点,转写结果无需后处理即可直接使用。
- 实时流式识别:端到端延迟控制在300ms以内,满足实时字幕、语音助手等交互需求。
- 开源可商用:采用MIT协议完全开源,提供预训练权重与PyTorch实现代码,支持二次开发。
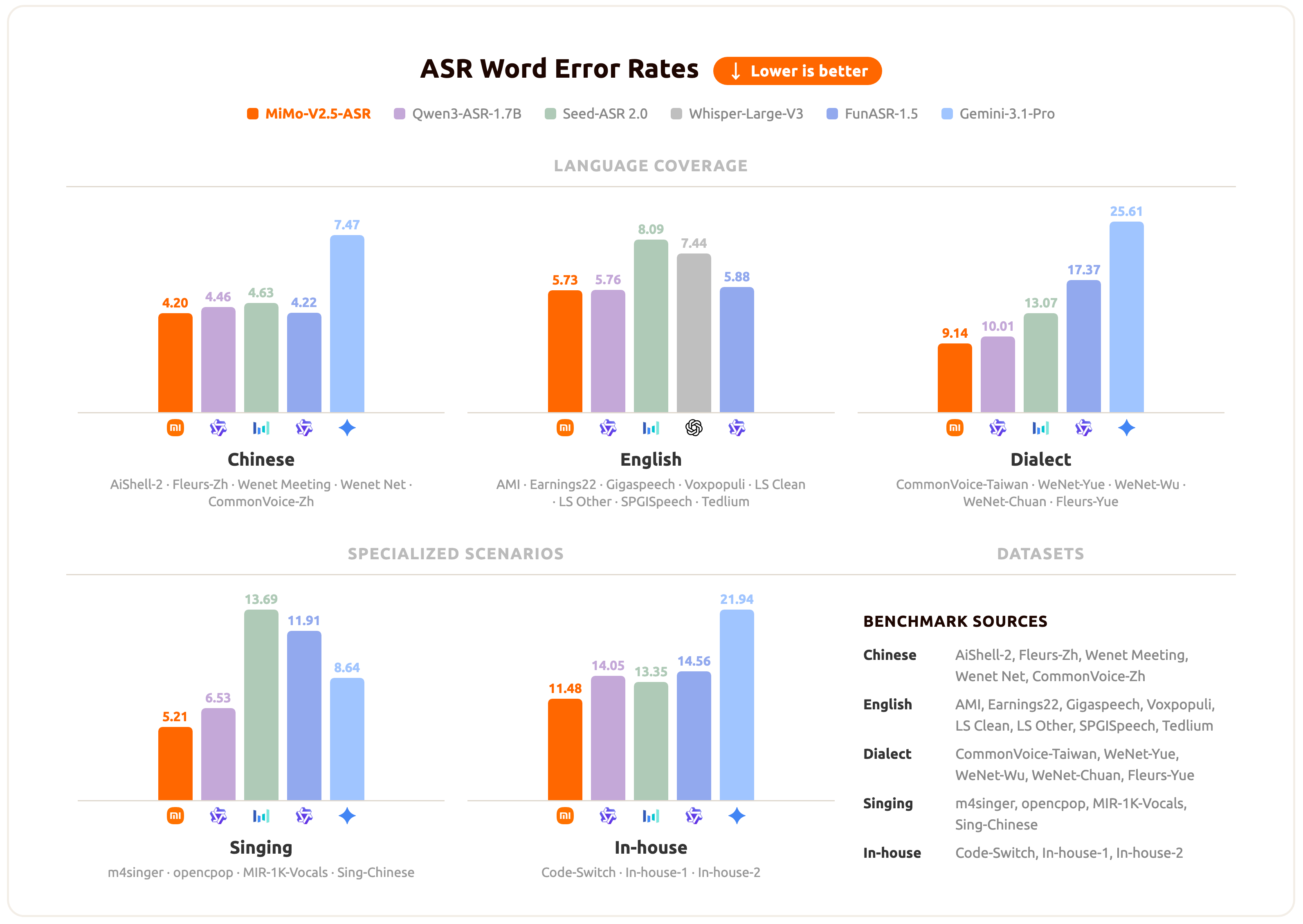
MiMo-V2.5-ASR技术原理
1. 多模态预训练架构
- 声学-语义联合建模:通过融合声学特征与上下文语义信息,解决传统ASR在专业术语、模糊发音场景中的歧义问题。
- 动态注意力机制:针对不同场景自适应调整声学特征权重,例如在噪音环境中强化频谱稳定区域的分析。
2. 复杂场景优化策略
- 方言嵌入层:为每种方言设计独立的声学适配模块,通过少量样本即可激活对应识别能力。
- Code-Switch边界检测:利用跨语言音素相似性建模,精准捕捉中英混说时的语种切换边界。
- 多人声纹分离:结合短时声纹聚类与对话逻辑分析,在无预先注册声纹的情况下区分说话人。
3. 推理效率优化
- 分级缓存机制:对重复出现的专业词汇(如品牌名、术语)建立本地化缓存库,降低长尾词错误率。
- 流式分段处理:采用滑动窗口式语音切片,在保证低延迟的同时维持长句语义连贯性。
MiMo-V2.5-ASR关键优势
1. 真实场景可靠性
- 免预设语种标签:用户无需手动切换中英文模式,模型自动适应混合语言输入,降低使用门槛。
- 抗干扰能力突出:在远场拾音、背景音乐干扰等场景下,错误率比主流开源模型低30%以上。
2. 生产流程提效
- 标点自动化节省60%后处理时间:原生输出带标点的文本,避免人工校对基础语法结构。
- 专业领域开箱即用:直接支持医疗、法律等垂直领域术语,减少定制化训练成本。
3. 开源生态友好性
- 轻量化部署:基础版可在消费级GPU上实时运行,适合嵌入车载、智能家居等终端设备。
- 无缝对接MiMo生态:与TTS系列模型协同工作,实现“语音输入-内容理解-语音输出”全链路闭环。
MiMo-V2.5-ASR应用场景
1. 企业级会议协作
- 智能会议记录:自动转录多人讨论内容,区分发言人并生成带时间戳的纪要,支持会后快速检索关键结论。
- 跨语言谈判辅助:实时识别中英混杂的商务对话,为翻译系统提供精准源文本。
2. 内容生产与教育
- 有声书制作:对方言评书、诗词朗诵等高艺术性语音进行高保真转写,保留情感韵律特征。
- 课堂语音转录:准确识别教师讲解中的专业术语与板书内容,生成结构化教学笔记。
3. 公共服务与无障碍场景
- 政务热线服务:在嘈杂的公共服务环境中精准捕捉市民诉求,自动归类至对应处理部门。
- 视障辅助工具:结合TTS模型,将实时环境语音转化为带标点的易读文本,提升无障碍交互体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...