
刷社交媒体的时候,看到一条消息——智谱发布了GLM-5.2。

嗯,又一个大模型更新。我差点划走。
但仔细一看数据,愣了。
这个开源模型,在一项叫FrontierSWE的工程能力测试里,爬到了全球第二。第一名是Claude Opus 4.8 ,第三名是 GPT-5.5 。一个开源的东西,夹在两个最贵的闭源模型中间,差了不到 1%。
离谱。
大家看到的是”又发了个模型”
媒体怎么报的?大概是这些关键词:100万上下文窗口、MIT开源协议、编程能力大幅提升。
普通人的反应大概是:哦,知道了。然后继续用ChatGPT或者Claude。
说实话,如果我不是一直在关注这个领域,我也会这么想。毕竟这两年大模型发布太多了,隔三差五就有一个“重磅发布”,麻了。
但这次不一样。
我看到的是”开源的快追上闭源的了”
让我换个说法你就懂了。
拿烧菜打个比方,米其林三星大厨确实厉害。但如果街边小馆子的师傅,做出来的口味评分只比米其林低 1 分,而且价格只有十分之一——你会怎么想?
GLM-5.2 现在就是那个街边师傅。菜谱是公开的,谁都能学。但灶台和食材还是要花钱的——只是比米其林便宜太多了。
具体数据说一下。在一个叫 FrontierSWE 的测试里,这个测试是让 AI 自己去完成一个完整的工程项目,从写代码到调试到优化,可能要花好几个小时。 GLM-5.2 拿了 74.4%, Claude Opus 4.8 是 75.1%, GPT-5.5 是 72.6%。
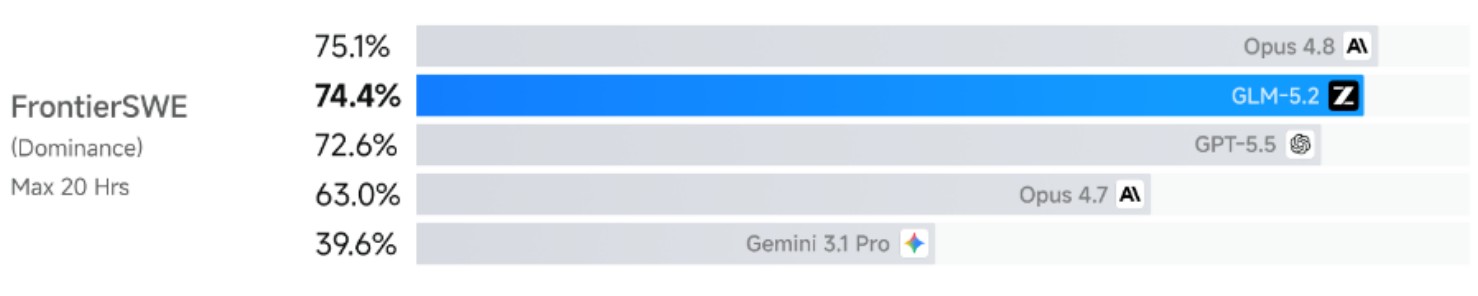
只差 0.7%。不到 1%。
另一个测试叫 PostTrainBench ,更狠——给每个模型一块 H100 显卡,让它自己想办法通过后训练提升小模型的性能。GLM-5.2 排第二,超过了 GPT-5.5 ,只输给 Opus 4.8 。

还有 Arena.ai 的前端代码排行榜,GLM-5.2 排第二,比 Claude Opus 4.7 高出 29 分。Agent Arena 排第十,跟 Claude Opus 4.8 几乎打平。
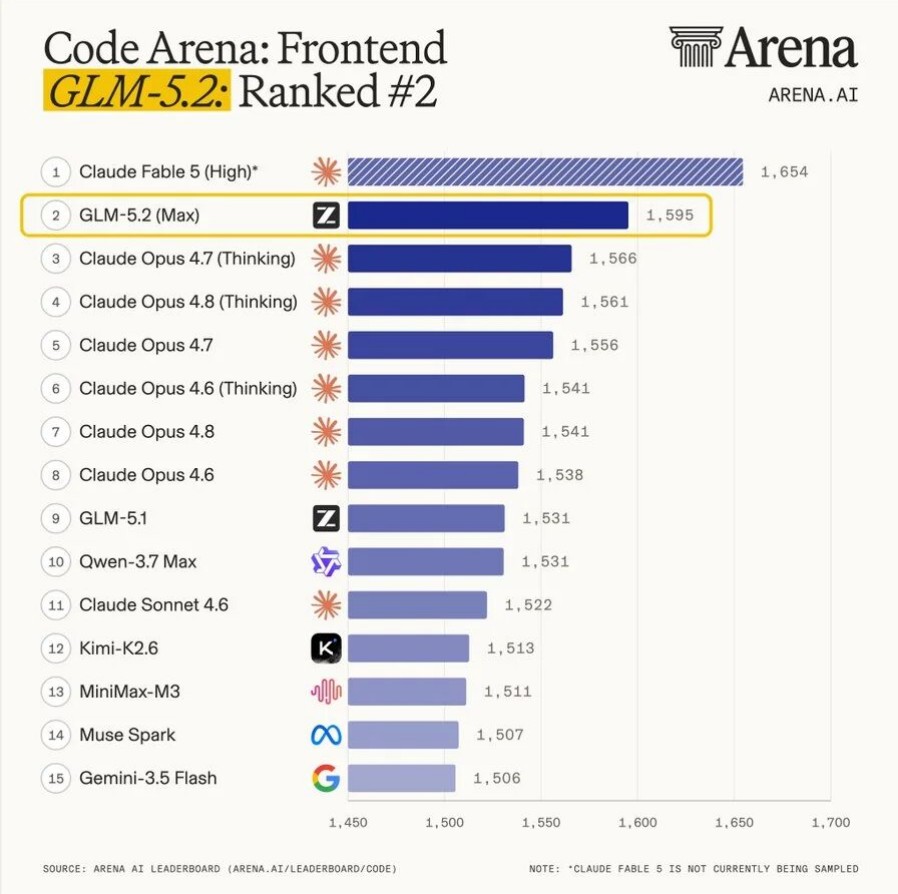
我看到这些数字的时候,第一反应不是”哇好厉害”,而是——等等,这东西是开源的?
对。 MIT开源协议。你可以下载模型权重,自己部署,想怎么用就怎么用。
但这里得说句实话。模型权重免费,不等于用起来免费。
自己跑一个100万上下文的大模型,光显卡成本就够买一辆车了。普通人根本不可能自己部署。
那开源有什么用?
用处大了。开源意味着任何公司都可以拿这个模型来提供服务。你不用自己买显卡,只需要用别人搭好的平台。而当市场上有多个平台都能提供差不多水平的服务时,价格战就来了。最终受益的是你我这种普通用户。
这对普通人意味着什么
也许你想说:我又不写代码,这些跟我有什么关系?
有关系。
你用AI写文案、做PPT 、整理资料、翻译文档——这些都需要大模型。目前市面上好用的模型,基本都是收费的。 Claude Pro 每月 20 美元,ChatGPT Plus 每月 20 美元,换成人民币一个月一百多。
对于我这种资金拮据的人来说,这笔钱不是小数目。
但如果开源模型的能力接近甚至追平了闭源模型,会发生什么?
会有更多公司拿开源模型来提供服务,竞争一激烈,价格就会往下走。就像当年安卓开源之后,千元智能机遍地开花一样。你不需要花 5000 块买 iPhone ,也能用微信、刷抖音、点外卖。
当然了,我不确定这件事一定会发生。也许大厂会想办法在生态上做壁垒。但趋势是清楚的——开源和闭源的能力差距,正在以肉眼可见的速度缩小。而能力差距越小,闭源模型收高价的理由就越站不住脚。
还有一个细节值得注意
GLM-5.2 有个“思考力度”调节功能。简单说就是你可以选择让 AI 慢慢想、想深一点,还是快速出结果。
这就像做菜——快餐 5 分钟出锅,年夜饭得炖两小时。不是所有场景都需要顶级大脑。你问 AI “明天天气怎么样”,不需要它深度推理;但你让它帮你写一份商业计划书,就需要它多想想。
这个设计我觉得挺聪明的。它意味着同一个模型可以覆盖不同场景,而不是“要么全速运转,要么就歇菜”。
说到底
我不觉得 Claude 或者 GPT 会被取代。至少短期内不会。这些闭源模型在很多细节上依然有优势,尤其是在复杂任务的稳定性上。
但方向已经很明确了。
两年前,开源模型跟闭源模型的差距,大概是大学生跟高中生的差距。一年前,变成了本科生跟研究生的差距。现在,是同一个导师带的两个学生,一个多考了 1 分。
这个变化的速度,比我预想的快得多。
也许再过半年,那个“1 分”的差距就没了。也许不会。但不管怎样,开源模型越来越能打,意味着我们用 AI 的成本会越来越低。对咱们普通用户来说,怎么都是好事。
至少下次有人跟我说“你得花钱买 XX 会员才能用好的”,我可以回一句:嗯,不一定了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...