autoresearch是Andrej Karpathy开源的AI自主研究框架,核心目标是让AI智能体完全替代人类执行模型训练实验的循环优化过程。其设计极为精简,通过固定5分钟实验时长、单一评估指标(val_bpb)和Git自动化流程,实现 “人类写Markdown指令,AI自主改代码跑实验” 的范式转变。
人类研究员只需在program.md中定义研究方向,AI即可通宵完成数百轮实验,自动筛选有效改进。该项目发布两天内获9.5k+ GitHub星标,并衍生出多智能体协作生态。
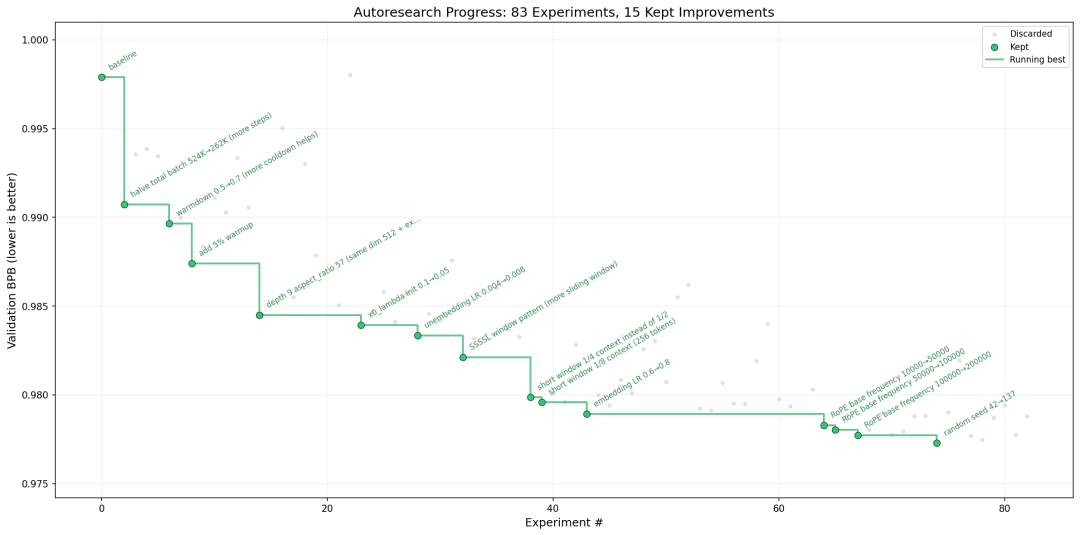
autoresearch核心设计与工作原理
1. 极简架构三要素
program.md:人类唯一需修改的文件,用自然语言编写研究指令(如”尝试调整注意力层结构”),AI据此生成实验策略。train.py:AI唯一可编辑的代码文件,包含模型架构、优化器及训练循环,所有修改仅限于此。prepare.py:固定数据准备与评估逻辑,人类与AI均不可修改,确保实验环境一致性。
2. 自主实验循环机制
- 5分钟严格时长限制:无论GPU性能或模型改动,每轮训练强制控制在5分钟墙钟时间,保证结果可比性。
- 单一评估指标:仅依赖
val_bpb(验证集每字节比特数) 作为决策依据,数值越低代表效果越好,避免多指标冲突导致的决策模糊。 - 自动化Git工作流:
- AI修改
train.py后提交实验代码; - 训练5分钟并记录
val_bpb; - 若指标下降则保留提交,否则
git reset回滚; - 结果自动写入
results.tsv,全程无需人工干预。
- AI修改
autoresearch核心突破与特点
1. 效率革命
- 通宵实验规模:按5分钟/轮计算,8小时可完成约96轮实验,远超人类手动迭代能力。
- 有效改进筛选:在Karpathy初始测试中,AI两天内完成276次实验,仅保留29项有效改进(占比10.5%),将模型训练效率提升约11%。
2. 去中心化协作扩展
- autoresearch@home:社区受SETI@home启发开发的分布式版本,支持多智能体异步协作,避免单一研究路径局限。
- 角色自发分化:80+智能体4天内完成2333次实验后,自动形成实验员、统计员、元分析员等分工,例如:
- 某智能体专注验证他人结论(188次/天);
- 另一组生成5895条假设但不执行实验。
3. 关键发现验证
- 批量大小与训练步数:将
batch_size减半(2^19→2^18)但加倍训练步数,val_bpb改善0.007,证明”更多step优于更大batch”。 - 架构优化瓶颈:群体智能发现最优配置为12层/512维度,加深网络(如16层)反而因步数减少导致性能下降。
- 噪声干扰警示:随机种子方差约0.002 val_bpb,许多声称的”改进”实为统计噪声,推动智能体自发要求多种子验证。
局限性与社区反馈
1. 当前能力边界
- 擅长执行而非创新:AI在超参数调优与架构微调上表现优异,但缺乏提出突破性研究方向的能力,仍需人类定义
program.md。 - 任务理解参差不齐:Karpathy自述其行为像”聪明的博士与十岁小孩的混合体“,可能连续成功20次实验后,在简单问题上陷入死循环。
2. 研究者实证评价
- 普林斯顿学者刘壮测试后指出:AI自主研究尚未达到可靠替代人类的程度。例如:
- 实验设计常流于表面,无法全面验证假设;
- 易忽略任务上下文(如忘记GPU分区限制);
- 过度依赖局部最优,缺乏长期探索策略。
行业影响与后续发展
1. 科研范式转变
- 从”人做实验”到”人设计做实验的AI”:研究员角色转向定义问题、约束条件及方向性指导,重复性调参工作被自动化。
- 预训练民主化:单GPU即可运行的轻量设计,使中小团队能参与模型优化竞争,降低AI研发门槛。
2. Karpathy的最新动向
- 2026年5月20日,Karpathy宣布加入Anthropic,专注于预训练团队,目标是”用Claude自身加速预训练研究“。
- 其核心任务正是将autoresearch理念延伸至大模型基础训练环节,探索AI辅助预训练的规模化路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...