Confucius4技术原理
1. 多模态模型架构
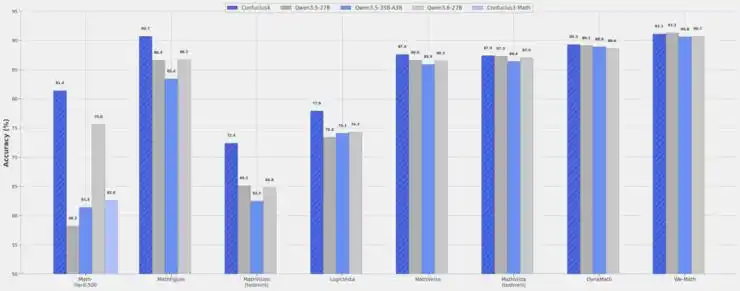
- 参数规模与训练目标:采用27B参数规模,专为教育场景优化,重点提升对带图表的数学、物理等视觉数理问题的解析能力,在多个基准测试中达到同规模模型的SOTA(最先进水平)。
- 思维链重构技术:通过汇聚大规模优质精简的推理样本进行深度优化,将思维链(CoT)输出长度压缩43.2%,实现更短的推理路径和更少的Token消耗。这一方案类似“草稿链”(CoD)思路,聚焦关键推理步骤而非冗余细节。
2. TTS语音合成模型
- 核心架构:基于“语音编码器+大语言模型(LLM)”的联合设计,支持零样本语音克隆与跨语言情感迁移。
- 关键机制:
- 跨语言音色保留:通过语音编码器提取说话人声学特征,结合LLM生成目标语言语音,无需额外训练即可实现14种语言间的音色一致性迁移。
- 情感精准还原:直接从输入音频中捕捉情感特征(如语调、节奏),迁移至合成语音中,实现“克隆情绪而非仅克隆声音”。
Confucius4核心优势
1. 性能与效率突破
- 推理成本大幅降低:思维链压缩技术使相同问题的Token消耗减少43.2%,推理速度更快且部署成本显著下降,更适合企业级落地。
- 视觉数理能力领先:在中文纯文本数理难题中准确率达81.4%,处理带图表的高难度问题表现优于同规模竞品模型。
2. 语音合成技术亮点
- 3秒极速克隆:用户仅需提供任意时长的音频素材,系统即可在3秒内完成零样本原声复制,克隆音色与原声相似度超过85%,任务准确率超97%。
- 跨语言无口音合成:支持中文、英语、日语等14种语言的无缝切换,合成语音无目标语言口音泄露(如中文音色说英语无“中式口音”)。
Confucius4主要功能
1. 多模态模型功能
- 教育场景专项优化:针对学生真实的作业、考试和提问场景深度调优,可解析含图表的数理题目并生成简洁解题步骤。
- 多模态交互支持:全面融合文本、图片、音频输入,实现复杂问题的跨模态理解与推理。
2. TTS模型功能
- 零样本语音克隆:无需参考文本,直接基于任意音频克隆音色。
- 情感迁移合成:精准复现输入音频中的情绪(如愤怒、喜悦),并迁移至目标语言语音中。
- 多语言实时生成:支持中、英、日、韩、德、法等14种语言的跨语种语音合成,适用于全球化内容生产。
Confucius4典型应用场景
1. 教育领域
- 智能辅导系统:为学生提供带图表解析的数理题解答,缩短推理步骤以提升学习效率。
- 语言学习工具:结合TTS模型生成多语言标准发音示范,辅助外语学习者纠正口音。
2. 开发者与企业应用
- 低成本AI服务部署:企业可基于开源模型快速搭建教育类应用,利用压缩后的推理路径降低服务器成本。
- 跨语言内容创作:媒体、游戏等行业通过TTS模型生成多语种配音,实现3秒克隆特定角色音色并迁移情感表达。
3. 文化传播场景
- 多语言文化输出:用于制作无口音障碍的中华经典诵读内容(如《论语》多语种语音版),适配“儒家经典跨语言诵读大会”等国际传播需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...