
GLM-5.1-highspeed技术原理
1. 核心引擎:TileRT高性能推理系统
- 编译期静态编排(AOT):彻底抛弃传统Runtime层的动态调度,在编译期将整个计算图静态编排为常驻GPU的persistent Engine Kernel,避免单token场景下因微秒级算子调度导致的冗余开销。
- Tile级微任务优化:在单卡内将计算、异步IO与通信拆解为细粒度微任务,中间结果通过寄存器/Shared Memory/L2 Cache直传,不再写回全局内存,消除90%以上的访存延迟。
- 多卡协同特化:将SM内部的Warp Specialization思路扩展至8卡NVL拓扑,不同GPU按计算密度与数据依赖被特化为异构worker,避免传统同构并行的资源闲置问题。
2. 系统级优化三层架构
- 推理引擎层:针对GLM-5.1架构重写核心推理路径,单卡吞吐能力提升30%以上,支持200K上下文与128K最大输出。
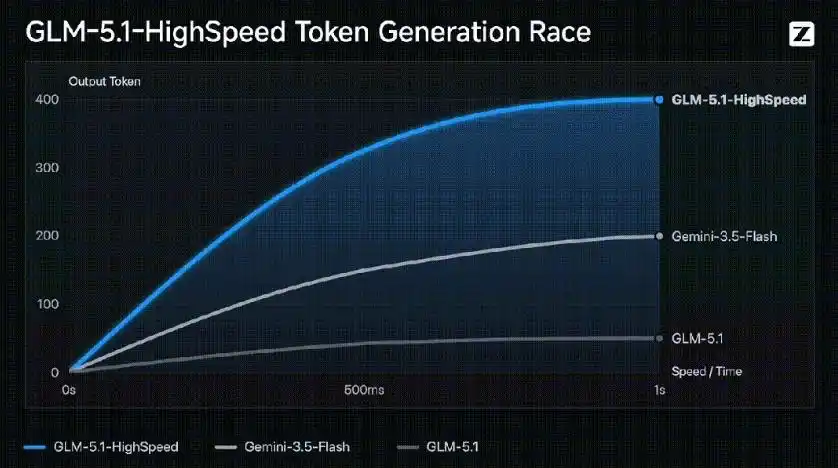
- 调度系统层:通过动态批处理、请求合并与KV缓存调度优化,显著降低高并发场景下的尾延迟,确保400 tokens/s的稳定性。
- 基础设施层:围绕推理集群部署、网络链路与负载均衡协同调优,将实验室峰值转化为生产级稳定输出,而非短暂性能爆发。
GLM-5.1-highspeed核心优势
1. 速度与能力的双重突破
- 400 tokens/s的稳定输出:相比普通版GLM-5.1(约40 tokens/s)提速10倍,且保持旗舰级模型能力(如SWE-bench Pro代码评测得分58.4%,全球开源模型第一)。
- 打破行业固有认知:首次证明高性能模型无需以牺牲响应速度为代价,解决过去“高速模型必为轻量级”的技术瓶颈。
2. 实时交互体验质变
- 多轮任务累计延迟归零:在需数十轮调用的Coding Agent任务中,单轮延迟从数秒压缩至毫秒级,整体耗时从“分钟级空等”变为“即问即答”。
- 瞬时场景联动能力:支持3D游戏中文字输入与场景实时动态建模,此前因延迟无法落地的交互形态具备可行性。
GLM-5.1-highspeed典型应用场景
1. AI编程与长程任务
- 实时代码协作:模型能一边理解工程上下文,一边持续生成代码与修改方案,开发者刚提出需求,函数接口与调用链已同步展开。
- 复杂网页快速生成:30秒内完成含多组件的复杂网页代码构建,大幅缩短传统开发流程中的等待时间。
2. 新型交互系统
- Agent Swarm并行调度:可瞬间调度50个不同人格的智能体并行回答,支持多角色协同决策,展现新型操作系统的雏形。
- 实时语音与商业决策:在语音对话、金融数据分析等场景中,响应延迟低于人类感知阈值(100ms内),实现真正无缝的交互体验。
3. 创新产品形态
- 动态3D环境生成:玩家在3D地图中移动并输入文字指令,模型实时调整场景结构(如“生成一座桥”立即改变地形)。
- 意图驱动的工具生成:用户提出需求的瞬间,模型即时生成匹配的交互工具(如自动生成数据看板),无需预设固定界面。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...