Ornith-1.0 是 DeepReinforce 团队推出的一个开源大语言模型系列,专为智能体编程任务而设计。创新在于一个自我改进的训练框架,使模型能够自主学习并优化指导其解决问题的“脚手架”(Scaffold),从而在各类编程基准测试中实现了开源模型中的顶尖性能。

Ornith-1.0 核心特点
- 自我改进能力:Ornith-1.0 的核心特点是其自我改进的训练策略。模型不仅学习如何解决问题,还学习如何生成和优化指导其解决问题的“脚手架”(Scaffold),形成一个持续优化的闭环。
- 全尺寸模型系列:提供从适合边缘设备部署的 9B 稠密模型,到追求极致性能的 397B 混合专家模型,覆盖了 9B-Dense、31B-Dense、35B-MoE 和 397B-MoE 四种不同规格。
- 顶尖的编程性能:在多项智能体编程基准测试中,Ornith-1.0 的性能超越了同等规模的开源模型,其旗舰模型 Ornith-1.0-397B 的表现甚至能与 Claude Opus 4.7 等顶尖闭源模型相媲美。
Ornith-1.0 技术原理
- 联合优化:在训练的每一步,模型会执行两个阶段的任务。首先,根据给定的任务和之前使用的脚手架,模型会提出一个改进后的新脚手架。然后,基于这个新脚手架和任务描述,模型生成解决方案。
- 奖励反馈:解决方案执行后获得的奖励会同时反馈给“脚手架生成”和“解决方案生成”两个阶段。这使得模型不仅被优化以产生更好的答案,还被优化以设计出能引出更好答案的“脚手架”。
- 防止奖励黑客攻击:为防止模型通过作弊(如直接读取测试文件答案)来获取奖励,该框架采用了三层防御机制:
- 固定外部边界:环境、工具接口和测试隔离是不可变的,模型只能优化其内部策略。
- 确定性监控:一个监控程序会强制执行边界,任何越界行为(如读取被隐藏的路径)都会导致奖励为零。
- LLM 法官否决:一个冻结的 LLM 法官会作为验证器之上的最终否决机制,防止模型在允许的工具范围内进行意图层面的“游戏”。
- 异步强化学习:为解决长流程任务中的离线策略问题,采用了流水线强化学习策略,并对较早生成的、可能已过时的 token 进行降权处理,以确保训练稳定性。
Ornith-1.0 主要功能
Ornith-1.0 的主要功能体现在其强大的智能体编程能力上,能够自主完成复杂的软件开发任务。
- 终端任务执行:在 Terminal-Bench 2.1 基准测试中,Ornith-1.0-397B 取得了 77.5 的高分,展现了其理解和执行复杂终端命令的能力。
- 软件工程任务解决:在 SWE-Bench Verified 基准测试中,Ornith-1.0-397B 获得了 82.4 分,证明其能够有效定位并修复真实世界软件仓库中的 bug。
- 多语言编程支持:在 SWE-Bench Multilingual 测试中表现优异,表明其具备处理多种编程语言的软件工程任务的能力。
- 资源高效部署:即使是 9B 参数量的 Ornith-1.0-9B 模型,其性能也能匹配甚至超越 Gemma 4-31B 等大得多的模型,使其非常适合在资源受限的边缘设备上部署。
Ornith-1.0 适用人群
- AI 研究人员与开发者:对于希望探索智能体训练、强化学习和自我改进机制的研究人员,Ornith-1.0 提供了一个优秀的开源研究平台。
- 软件开发团队:希望利用 AI 智能体来自动化代码修复、测试、重构等任务的团队,可以采用 Ornith-1.0 来提升开发效率。
- 边缘计算应用开发者:需要在本地设备(如个人电脑、移动设备)上运行高性能编程模型的开发者,可以选择 Ornith-1.0-9B 等轻量级模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
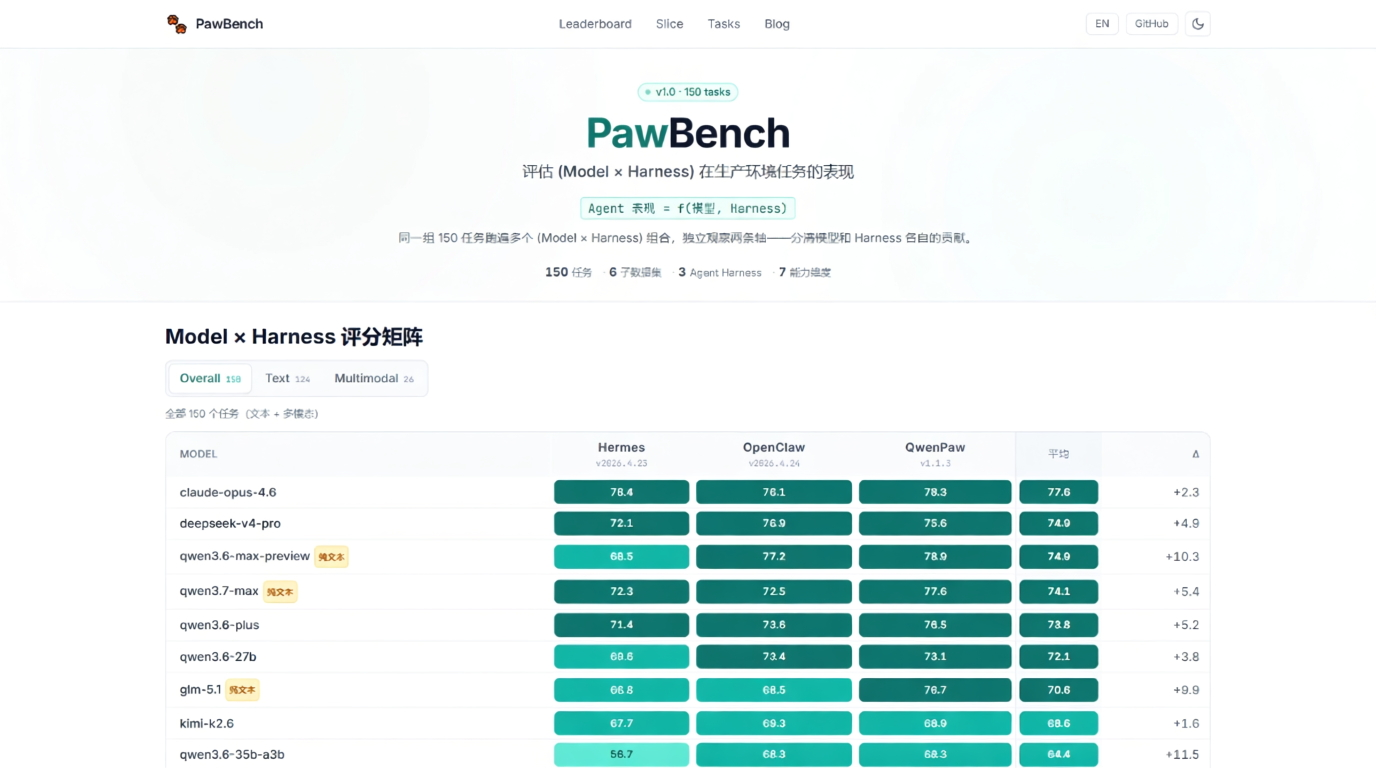

暂无评论...