Mellum2是JetBrains推出的120亿参数开源混合专家(MoE)模型,专为软件工程场景设计,核心目标是通过超低延迟推理与私有化部署能力,解决企业级AI工作流中的实时性与成本瓶颈。
Mellum2并非追求参数规模的前沿大模型,而是聚焦代码生成、工具调用与智能体工作流的高效执行组件,在保持高性能的同时将推理成本降低50%以上,尤其适合需本地化部署的开发环境。
Mellum2核心特点
1. 高效参数设计
- 总参数120亿,但每Token仅激活25亿参数:采用稀疏混合专家(MoE)架构,通过动态路由机制选择最相关的专家子网络,显著减少单次推理的计算量。
- 128K超长上下文窗口:上下文长度从初代Mellum的8K提升至131,072 tokens,可完整处理大型代码库、技术文档及跨文件上下文。
2. 功能定位升级
- 从代码补全到完整智能编码助手:不再局限于单行补全,支持生成/编辑代码、调用外部工具(如API查询)、执行多步骤任务规划,并具备显式推理能力(如分步调试逻辑)。
- 双模式运行机制:
- 非思考模式(Non-thinking):快速响应简单补全请求。
- 思考模式(Thinking):针对复杂任务启动多步骤推理链,输出更精准结果。
Mellum2核心优势
1. 性能与成本优化
- 推理速度提升50%以上:在同等硬件条件下,输出吞吐量达到同规模稠密模型的2倍,延迟降低至毫秒级,满足IDE实时交互需求。
- 推理成本减半:因激活参数量大幅减少,单次请求的算力消耗与能源成本显著下降,适合高频调用的生产环境。
2. 企业级部署友好性
- 完全开源可商用:基于Apache 2.0协议发布,允许私有化部署、自由微调及商业化集成,无数据外泄风险。
- 标准硬件兼容:无需高端GPU集群,可在常规服务器甚至本地开发机高效运行,降低企业部署门槛。
3. 垂直领域精准适配
- 代码与数学专项优化:训练数据采用三阶段课程学习,逐步从通用文本过渡到代码、数学及工程文档,在软件开发任务中表现优于通用大模型。
- 工具调用能力突出:在BFCL V4工具调用评测中,思考模式得分达45.6,显著高于同规模模型(如Qwen3.5-9B的42.7)。
Mellum2技术原理
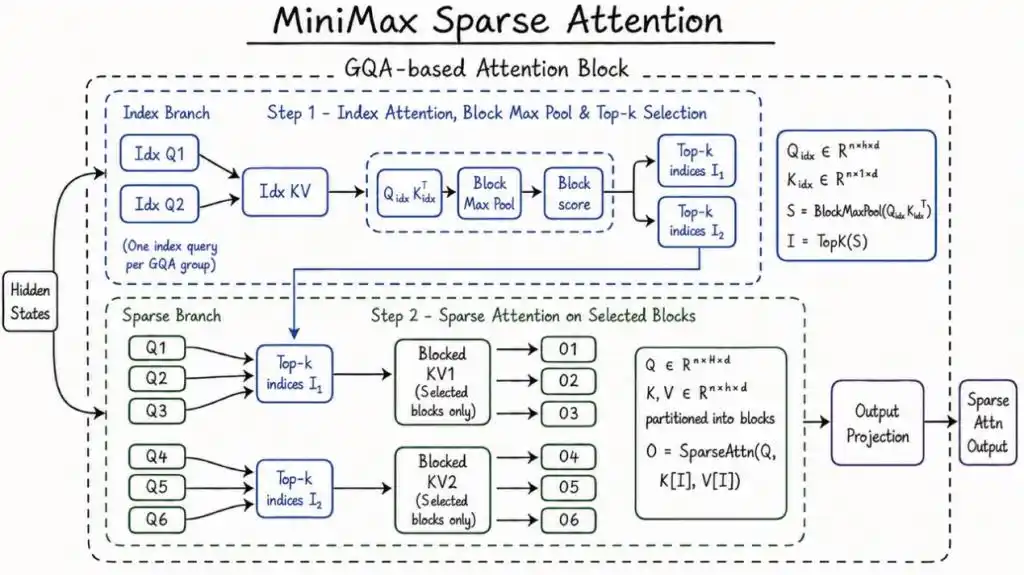
1. 稀疏混合专家(MoE)架构
- 动态专家路由机制:输入Token通过门控网络自动分配至最相关的8个专家子网络(共64个专家),仅激活约25亿参数。
- 计算效率提升:相比全参数激活的稠密模型,相同任务下GPU占用减少40%以上,同时避免MoE常见的负载不均衡问题。
2. 训练策略创新
- 三阶段渐进式课程学习:
- 基础语义阶段:使用多样化网络文本建立通用语言理解。
- 代码强化阶段:逐步增加代码与数学数据比重,提升逻辑推理能力。
- 工程专项阶段:聚焦软件工程场景,优化API调用、调试等任务表现。
- 长上下文优化:采用YaRN技术扩展上下文窗口,避免传统位置编码在长序列中的性能衰减。
3. 智能体工作流支持
- 任务分解与编排:可将复杂目标(如“修复整个模块”)拆解为可执行的子任务序列(定位错误→生成补丁→验证结果)。
- 外部工具链集成:直接调用代码解释器、依赖管理器等工具,实现端到端任务闭环,无需人工干预。
Mellum2应用场景
1. 开发效率增强
- 实时智能编码助手:在IDE中提供跨文件上下文感知的代码生成与重构建议,支持长对话记忆,避免重复解释需求。
- 自动化调试与修复:根据错误日志自动生成修复方案并验证补丁有效性,大幅缩短问题解决周期。
2. 企业级AI系统构建
- 低延迟RAG系统核心:快速检索代码库文档并实时生成精准答案,适用于内部知识库问答。
- 智能体工作流引擎:在复杂Agent系统中承担高频子任务(如上下文收集、步骤验证),释放大模型资源处理核心逻辑。
3. 数据敏感场景落地
- 私有化代码辅助:在金融、医疗等对数据安全要求严苛的领域,实现完全离线的代码生成与分析,避免敏感信息外传。
- 本地化AI工具链:作为企业自研AI平台的底层组件,支持定制化微调以适配内部技术栈(如专有API规范)。
Mellum2同类竞品对比
| 对比维度 | Mellum2 | Qwen3.5-9B | SeedCoder-8B |
|---|---|---|---|
| 模型架构 | 12B MoE(64 专家,8 激活,2.5B 活跃参数) | 9B 密集模型(Dense) | 8B 密集模型(Dense) |
| 开源协议 | Apache 2.0(完全可商用) | 开源(可商用) | 未明确/部分受限 |
| 模态支持 | 仅文本 + 代码(垂直专精) | 文本、代码、图像、视频(多模态通用) | 仅代码(单领域) |
| 每 Token 计算量 | ≈2.5B 参数(极低) | 9B 参数(全量激活) | 8B 参数(全量激活) |
| LiveCodeBench v6 | 69.9(Thinking) | 68.3(Thinking) | 28.1(Non-thinking) |
| BFCL V4 工具调用 | 45.6(Thinking) | 42.7(Thinking) | N/A(不支持) |
| AIME 数学推理 | 58.4(Thinking) | 73.4(Thinking) | 0(不支持) |
| 上下文长度 | 128K(YaRN 扩展) | 128K+ | 通常 4K-8K |
| 推理模式 | 双模式:Thinking + Non-thinking | 双模式:Thinking + Non-thinking | 仅 Non-thinking |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...