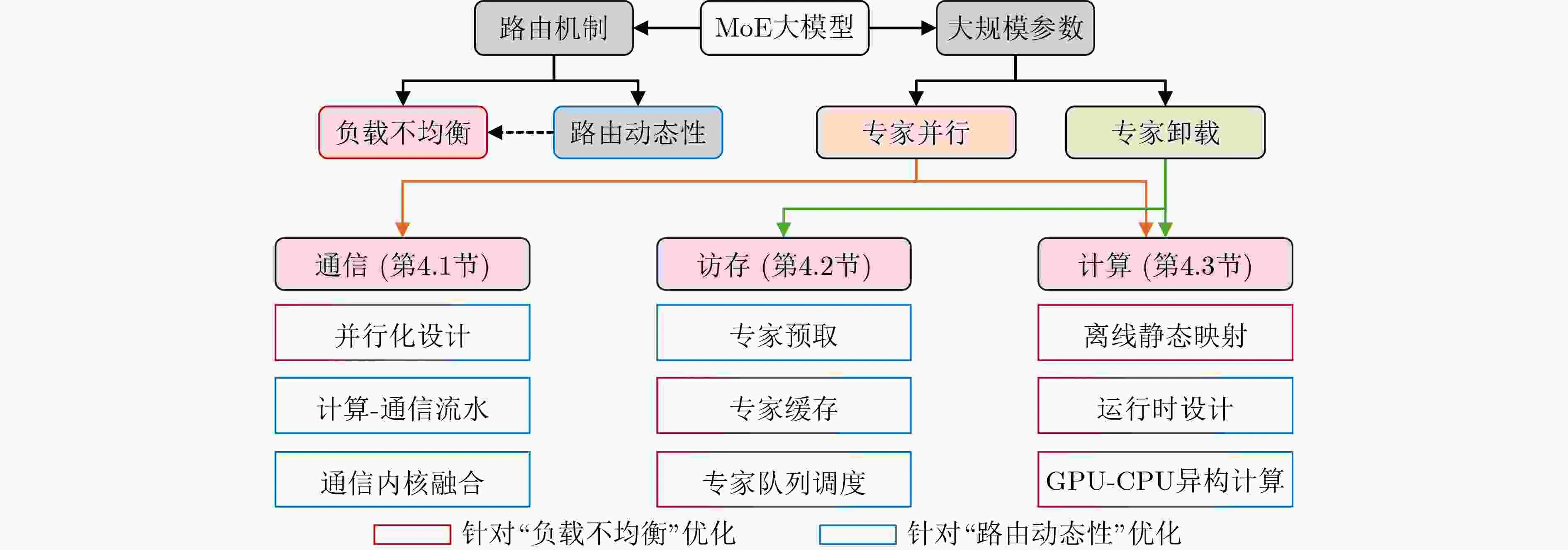
稀疏混合专家(MoE)架构
稀疏混合专家(Sparse Mixture of Experts, Sparse MoE)架构是当前大模型实现“参数规模扩展”与“推理成本控制”平衡的关键技术。 简单来说,它通过“分而治之”的策略,构...
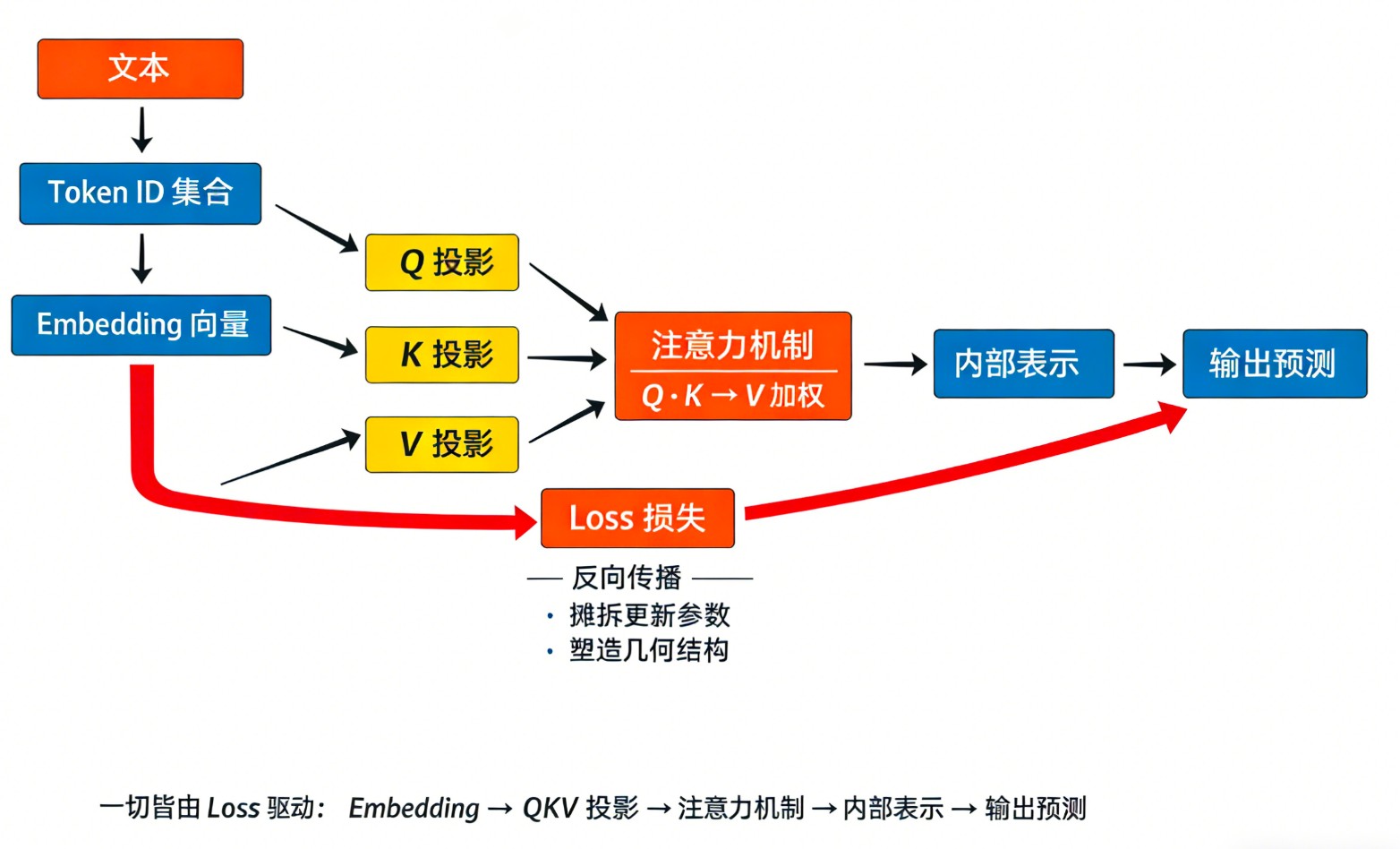
标准注意力机制
标准注意力机制,通常指缩放点积注意力(Scaled Dot-Product Attention),是现代大模型(如Transformer、GPT系列)的基石。 它的核心思想非常直观:模拟人类“聚焦重点...
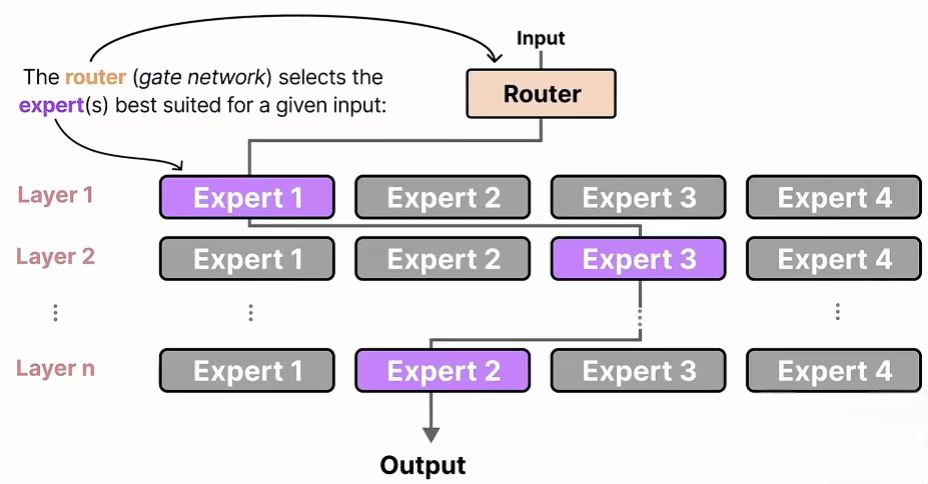
混合专家MoE模型
混合专家(Mixture of Experts, MoE)模型是当前大模型领域最核心的架构创新之一。它通过一种“分而治之”的策略,成功破解了模型规模与计算成本之间的矛盾,让打造性能更强、效率更高的AI...

Qwen3.6-35B-A3B – 阿里通义千问开源混合专家(MoE)模型
Qwen3.6-35B-A3B是阿里巴巴通义千问团队于2026年4月16日正式开源的一款高性能混合专家(MoE)模型。 作为Qwen3.6系列的首个开源权重版本,它凭借“350 亿总参数、仅30亿激活...
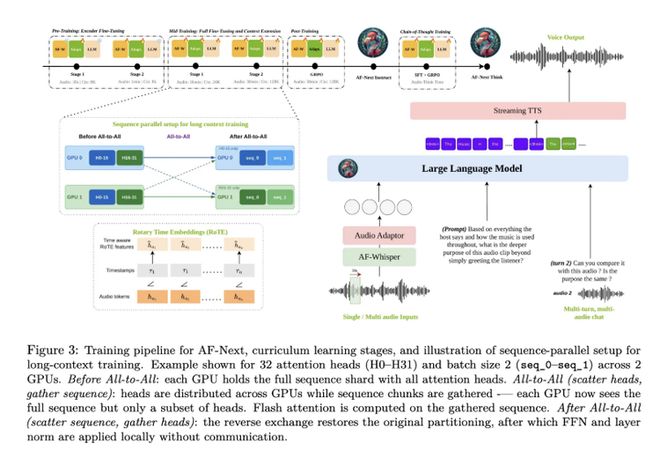
Audio Flamingo Next – 深度解析NVIDIA开源的AF-Next架构与能力
Audio Flamingo Next (AF-Next) 是由 NVIDIA(英伟达)与马里兰大学研究团队在2026年4月联合发布的最新开源大型音频语言模型(LALM)。 它是Audio Flami...

通用推理引擎
通用推理引擎(General Reasoning Engine)代表了人工智能发展的一种新范式,它旨在超越当前主流的聊天机器人或内容生成模型,成为一个可审计、可验证的通用问题求解器。 与追求“全知全能...
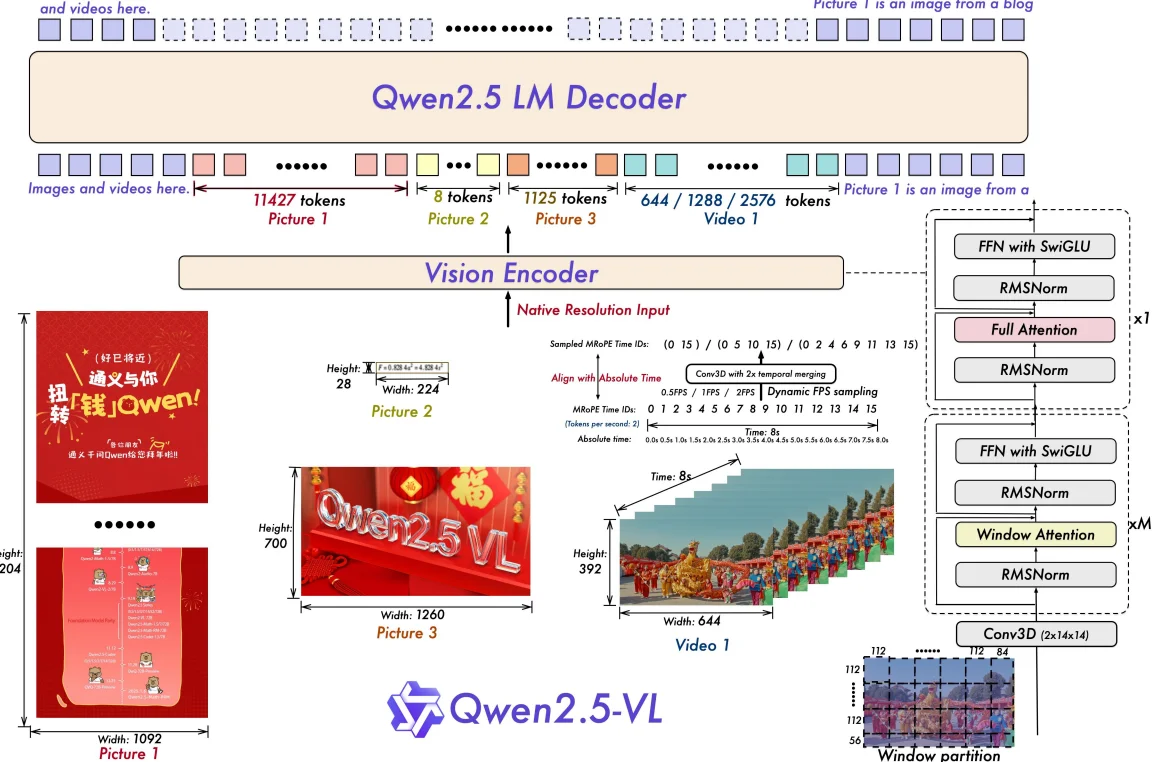
Qwen2.5-VL – 通义千问团队发布的旗舰级视觉语言模型
Qwen2.5-VL 是阿里巴巴通义千问团队发布的旗舰级视觉语言模型(Vision-Language Model),它在多模态理解、精确目标定位、文档解析和长视频理解等方面实现了显著的技术飞跃。 核心...
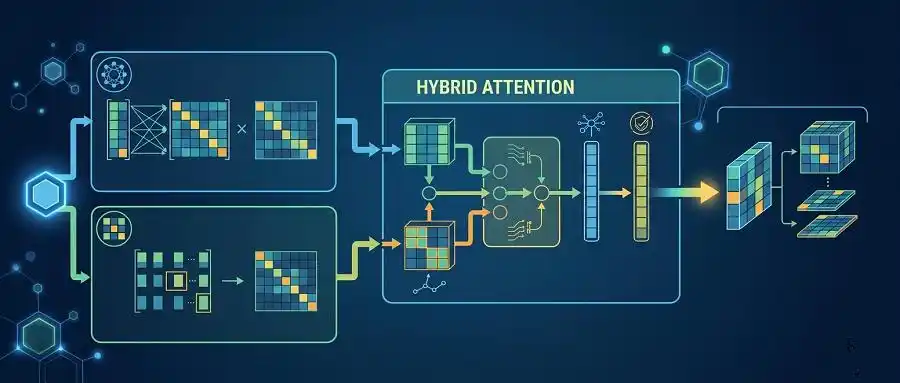
混合注意力机制是什么
混合注意力机制(Hybrid Attention Mechanism)是当前大模型架构演进中的一个关键突破,旨在解决传统标准注意力机制在处理超长序列时计算成本过高(O(n²))的瓶颈。 简单来说,它不...
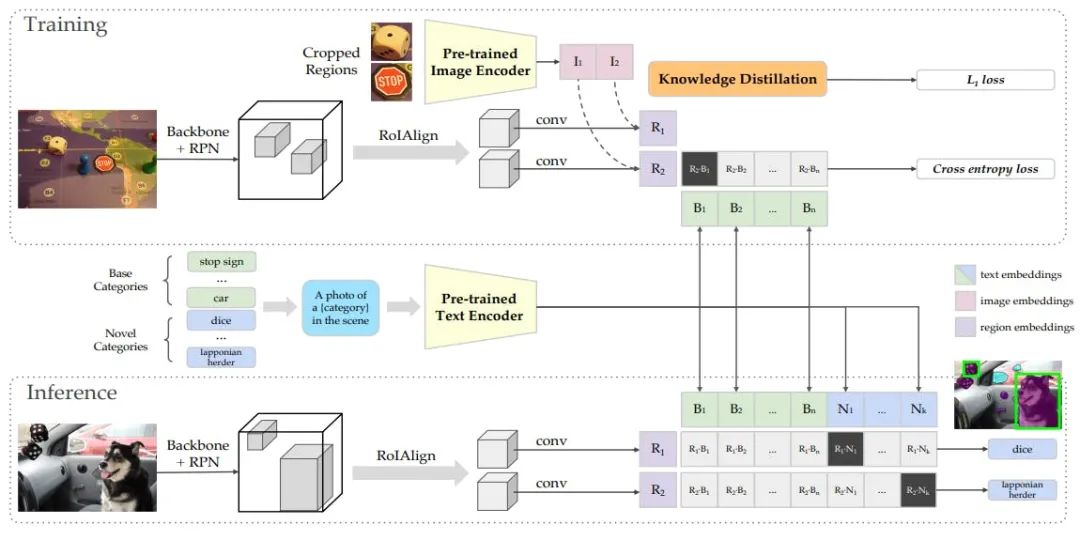
视觉语言模型和多模态大模型的区别在哪
视觉语言模型(VLM)和多模态大模型(MLLM)的核心区别在于能力范围和技术架构。简单来说,VLM是专注于“看懂”图像并“说出”内容的专家,而MLLM则是在此基础上,以强大的语言模型为核心,能够处理和...
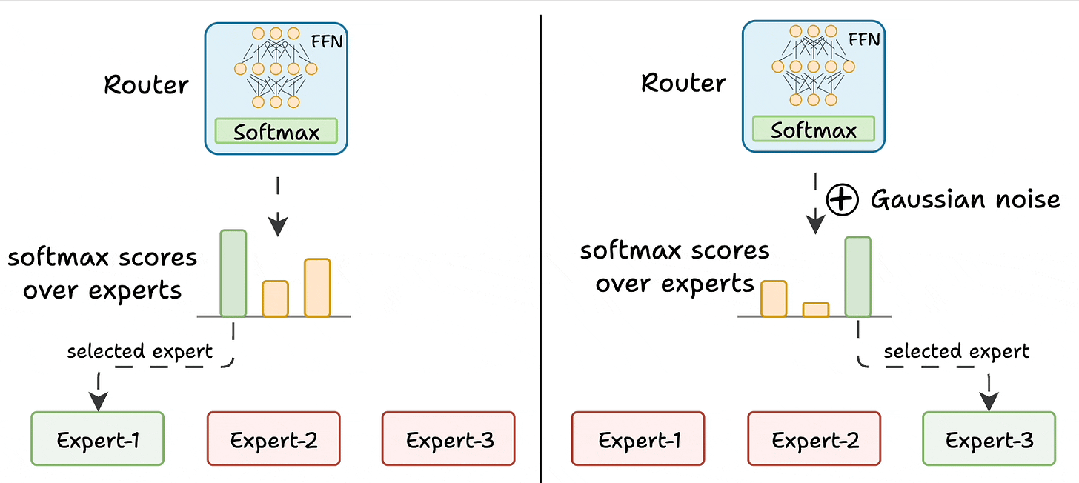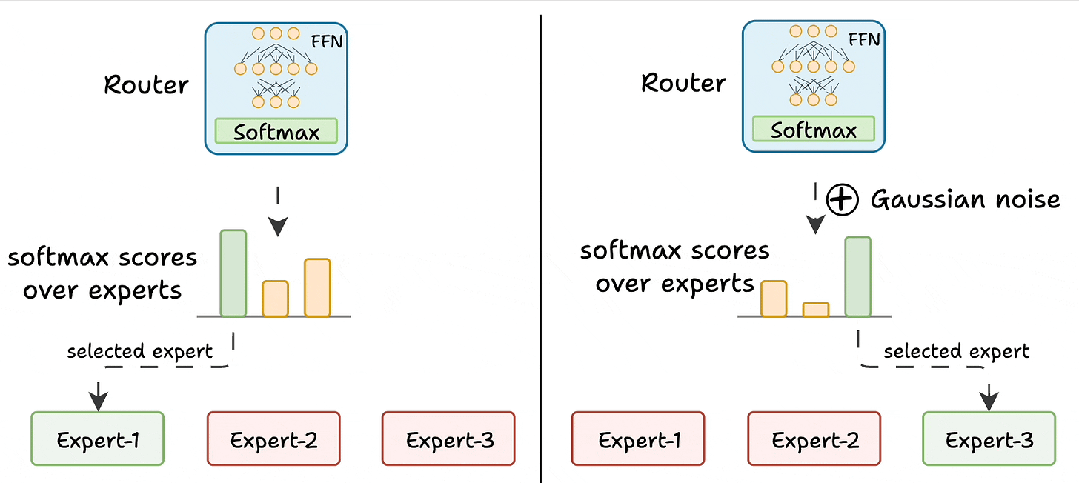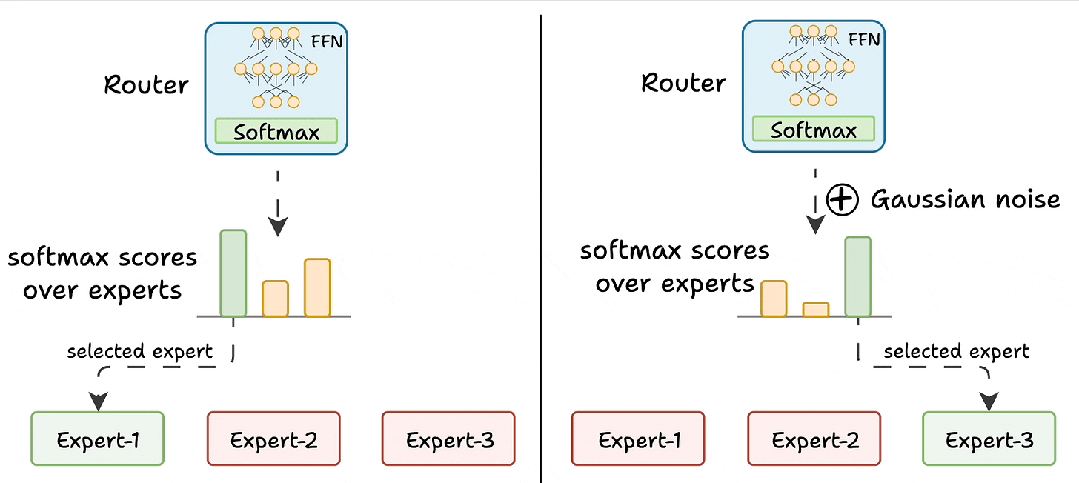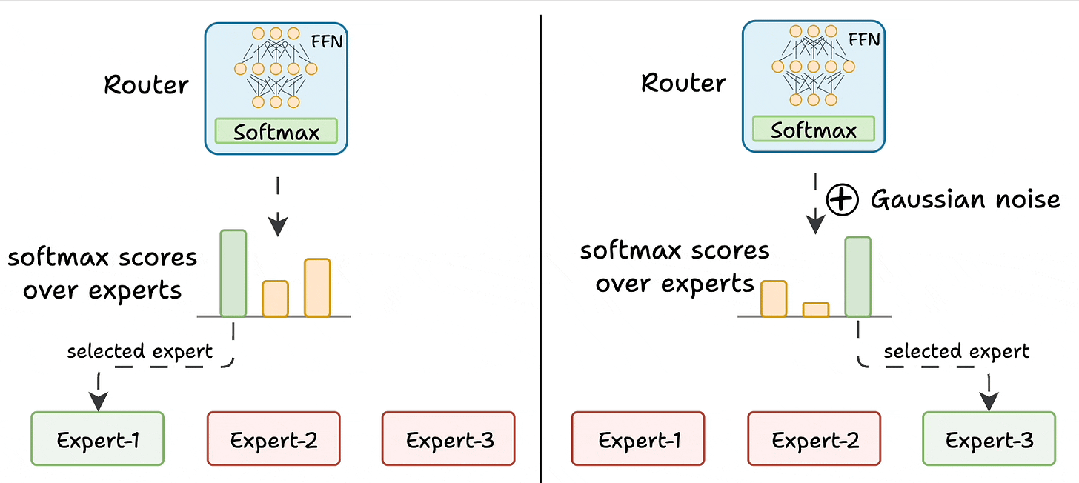
什么是混合注意力专家 – 一文读懂大模型架构新趋势
这其实是当前大模型架构(尤其是像Qwen2.5-VL这类视觉语言模型)里,为了解决“既要看得清细节,又要算得快”这个矛盾而采用的一种混合架构设计。它并不是指某一个具体的模型名字,而是指一种将混合注意力...